
00.Kubeflow源码分析(定义和功能介绍)
Kubeflow源码分析(定义和功能介绍)
文章基于V1.10.0版本进行分析
Kubeflow是什么
Kubeflow 是一个基于 Kubernetes 的开源机器学习平台,旨在简化和加速机器学习(ML)工作流的开发、部署和管理。Kubeflow 通过将机器学习任务容器化、自动化,并在 Kubernetes 集群上高效地运行,帮助企业和开发者在大规模环境下实现端到端的机器学习生命周期管理。
Kubeflow 有什么用途?
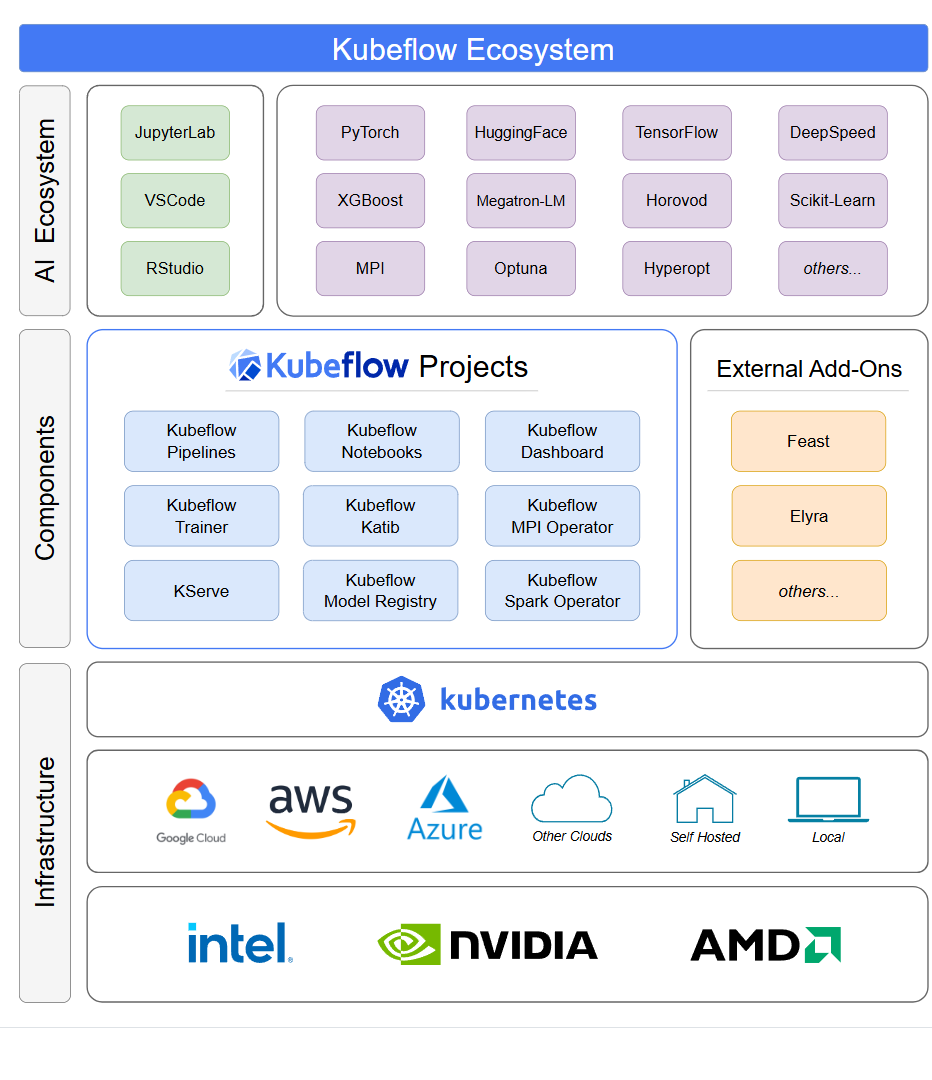
Kubeflow 通过提供一系列工具和 API 来简化大规模训练和部署 ML 模型的过程,可以解决机器学习管道编排过程中涉及的诸多挑战。“pipeline”表示 ML 工作流,包括工作流的组件以及这些组件之间的交互方式。Kubeflow 能够满足一个项目中多个团队的需求,并允许这些团队从任何基础架构工作。这意味着,数据科学家可以从自己选择的云(包括 IBM Cloud、Google Cloud、Amazon 的 AWS 或 Azure)进行训练和提供 ML 模型。
总的来说,Kubeflow 通过组织项目,同时利用云计算的强大功能,实现了机器学习运维(MLOp)的标准化。Kubeflow 的一些关键用例包括数据准备、模型训练、评估、优化和部署。
Kubeflow 的核心功能
- 端到端机器学习工作流管理
支持从数据准备、模型训练、超参数调优,到模型部署、监控的全流程自动化和可追溯。 - 可扩展性和可移植性
构建在 Kubernetes 之上,支持在本地、云端或混合环境中无缝运行和迁移。 - 多框架支持
原生支持 TensorFlow、PyTorch、XGBoost、MXNet 等主流机器学习框架。 - 分布式训练
支持分布式训练任务的调度和管理,适合大规模数据和复杂模型。 - 可视化和协作
提供基于 Web 的用户界面(如 Kubeflow Central Dashboard)和实验管理工具,便于团队协作和模型追踪。
Kubeflow 的主要组件
Kubeflow 由多个松耦合的组件组成,每个组件负责机器学习生命周期中的某一环节。常见组件包括:
- Kubeflow Pipelines
让用户能够以有向无环图(DAG)的形式定义和执行复杂的 ML 工作流。Kubeflow Pipelines 提供了一种方法,可编排并自动执行数据预处理、模型训练、评估和部署的端到端流程,从而促进了 ML 项目的可重现性、可扩展性和协作性。Kubeflow Pipelines SDK 是一组 Python 软件包,允许用户精确而高效地定义和执行机器学习工作流。 - Katib
自动化超参数调优(AutoML),支持多种搜索算法和早停机制。 - KFServing(现更名为 KServe)
支持模型的在线推理服务,支持弹性伸缩、A/B 测试和多种框架。 - Notebook Servers
提供基于 Jupyter Notebook 的开发环境,便于数据探索和模型开发。 - Training Operators
如 TensorFlow Operator、PyTorch Operator、MXNet Operator,用于调度和管理不同框架的分布式训练任务,用户可以利用 Kubernetes 的可扩展性和资源管理功能,跨机器集群高效地训练模型。 - Central Dashboard
Kubeflow 的统一 Web UI,集中管理各类资源和组件。 - Metadata
记录和管理机器学习过程中的元数据,便于实验追踪和结果复现。 - Fairing
用于简化本地开发向 Kubeflow 工作流的集成(目前已部分合并进 Pipelines)。
| 组件 | 描述 | Repository |
|---|---|---|
| Central Dashboard | Kubeflow 的统一 Web UI,集中管理各类资源和组件。 | kubeflow/dashboard |
| Notebooks | 提供基于 Jupyter Notebook 的开发环境,便于数据探索和模型开发。 | kubeflow/notebooks |
| Pipelines | 让用户能够以有向无环图(DAG)的形式定义和执行复杂的 ML 工作流。Kubeflow Pipelines 提供了一种方法,可编排并自动执行数据预处理、模型训练、评估和部署的端到端流程,从而促进了 ML 项目的可重现性、可扩展性和协作性。Kubeflow Pipelines SDK 是一组 Python 软件包,允许用户精确而高效地定义和执行机器学习工作流。 | kubeflow/pipelines |
| Katib | 自动化超参数调优(AutoML),支持多种搜索算法和早停机制。 | kubeflow/katib |
| Training Operator | 如 TensorFlow Operator、PyTorch Operator、MXNet Operator,用于调度和管理不同框架的分布式训练任务,用户可以利用 Kubernetes 的可扩展性和资源管理功能,跨机器集群高效地训练模型。 | kubeflow/training-operator |
| KServe | 支持模型的在线推理服务,支持弹性伸缩、A/B 测试和多种框架。 | kserve/kserve |
| Profile Controller | Multi-user isolation and resource management | kubeflow/dashboard |
| Model Registry | Registry for ML models | kubeflow/model-registry |
| Spark Operator | Spark 任务管理,通常用于预训练 | kubeflow/spark-operator |
因为结合了 Kubernetes Operator 模型,Kubeflow 具有可扩展性,并支持自定义以适应特定的用例和环境。用户可以集成其他组件,如数据预处理工具、特征平台、监控解决方案和外部数据源,以增强其 ML 工作流的功能。
ML生命周期
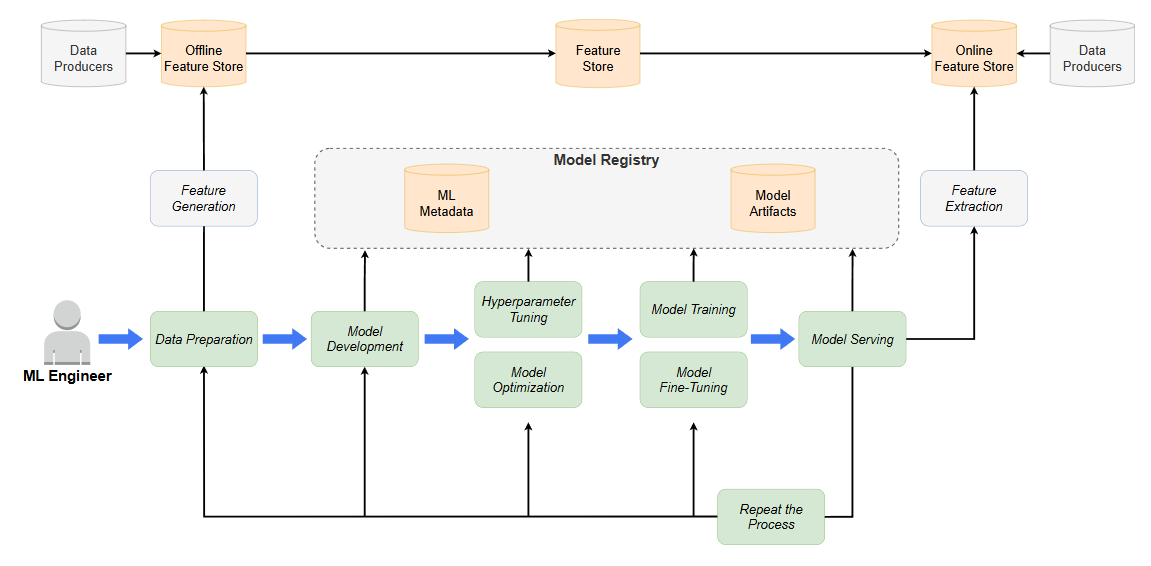
结合Kubeflow组件的ML生命周期
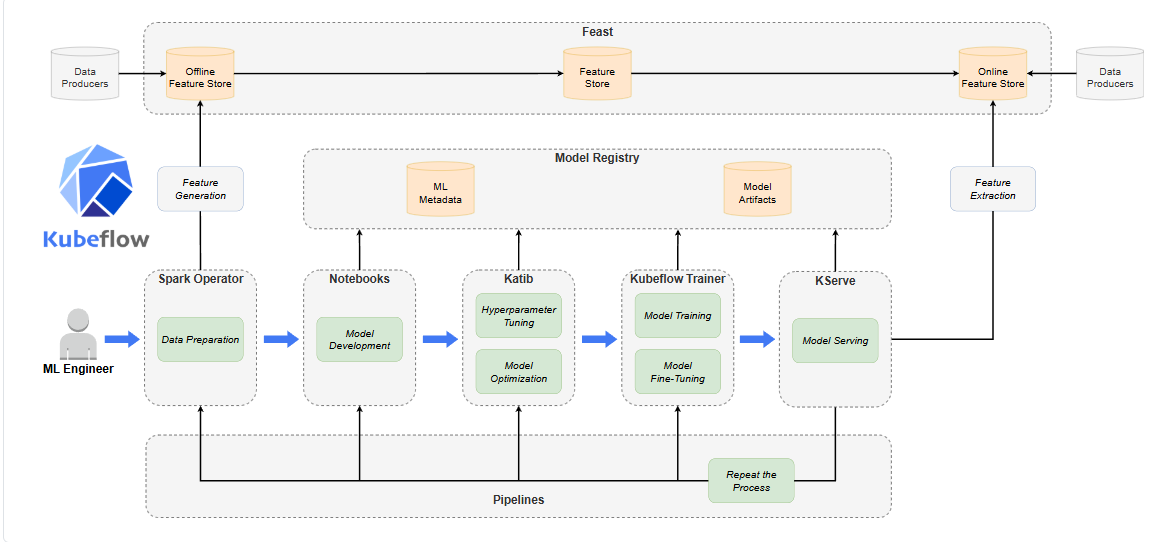
总结
Kubeflow 是一个专为 Kubernetes 生态设计的机器学习平台,聚合了数据科学、ML 工程师和运维人员在机器学习项目中的各项需求。通过集成上述组件,Kubeflow 实现了端到端的 ML 生命周期管理,提升了开发效率和生产环境的可靠性。
如果你有具体应用场景或遇到部署问题,欢迎进一步提问!