hashicorp raft源码分析(二、日志复制与安全性实现)
本文基于 hashicorp/raft v1.7.3 版本进行源码分析
API手册:https://pkg.go.dev/github.com/hashicorp/raft
源码地址:hashicorp/raft
raft论文中文解读:https://github.com/maemual/raft-zh_cn/blob/master/raft-zh_cn.md
在阅读文章前需要有一定的 raft 基础, 不然直接看源码会一头雾水.
上一篇文章:hashicorp raft源码分析(一、项目介绍与Leder选举实现)
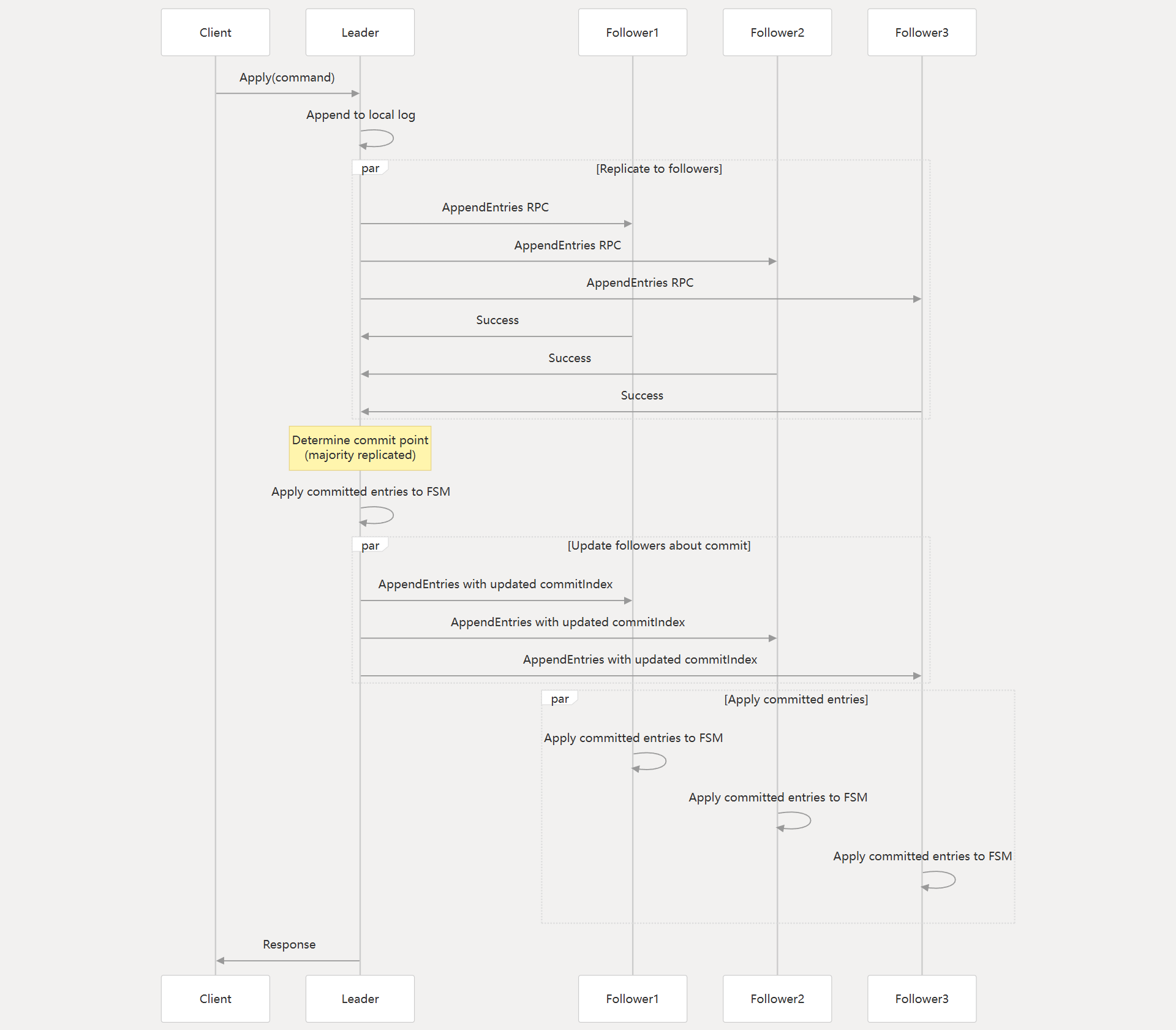
一、日志复制(Log Replication) 本文按照下面流程分析 raft 日志复制的实现原理.
调用上层 Apply 接口写数据.
leader 向 follower 同步日志.
follower 接收日志.
leader 确认提交日志, 并且应用到状态机.
follower 确认提交日志.
Apply 方法应用日志,写入applyCh通道中 Apply 是 hashicorp raft 提供的给上层写数据的入口, 当使用 hashicorp/raft 构建分布式系统时, 作为 leader 节点承担了写操作, 这里写就是调用 api 里的 Apply 方法.
Apply 入参的 cmd 为业务需要写的数据, 只支持 []byte, 如是 struct 对象则需要序列化为 []byte, timeout 为写超时, 这里的写超时只是把 logFuture 插入 applyCh 的超时时间, 而不是推到 follower 的时间.
Apply 其内部流程是先实例化一个定时器, 然后把业务数据构建成 logFuture 对象, 然后推到 applyCh 队列. applyCh 缓冲队列的大小跟 raft 的并发吞吐有关系的, hashicorp raft 里 applyCh 默认长度为 64.
代码位置: github.com/hashicorp/raft/api.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func (r *Raft) byte , timeout time.Duration) ApplyFuture {return r.ApplyLog(Log{Data: cmd}, timeout)func (r *Raft) var timer <-chan time.Timeif timeout > 0 {select {case <-timer:return errorFuture{ErrEnqueueTimeout}case <-r.shutdownCh:return errorFuture{ErrRaftShutdown}case r.applyCh <- logFuture:return logFuture
监听 applyCh 并调度通知日志 leaderLoop 会监听 applyCh 管道, 该管道的数据是由 hashicorp/raft api 层的 Apply 方法推入, leaderLoop 在收到 apply 日志后, 调用 dispatchLogs 来给 replication 调度通知日志.
代码位置: github.com/hashicorp/raft/raft.go
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func (r *Raft) for r.getState() == Leader {select {case ...:case newLog := <-r.applyCh:for i := 0 ; i < r.config().MaxAppendEntries; i++ {select {case newLog := <-r.applyCh:append (ready, newLog)default :break GROUP_COMMIT_LOOPcase ...:
dispatchLogs 是 Raft 协议中 Leader 节点用于处理日志分发的核心方法
日志持久化 :
将日志写入本地磁盘,确保日志的持久化。如果写入失败,Leader 节点会降级为 Follower 节点,并通知调用者操作失败。
状态更新 :
commitment.match 来计算各个 server 的 matchIndex, 计算出 commit 提交索引.
更新 Leader 节点的匹配索引(match index),表示本地节点已成功存储日志。
更新 Leader 节点的最后日志索引和任期信息。
触发日志复制 :
异步通知所有 Follower 节点的复制器,触发日志复制流程,确保日志被同步到集群中的其他节点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 func (r *Raft) defer metrics.MeasureSince([]string {"raft" , "leader" , "dispatchLog" }, now)len (applyLogs) make ([]*Log, n) string {"raft" , "leader" , "dispatchNumLogs" }, float32 (n))for idx, applyLog := range applyLogs {if err := r.logs.StoreLogs(logs); err != nil {"failed to commit logs" , "error" , err)for _, applyLog := range applyLogs {return for _, f := range r.leaderState.replState {
replicate 同步日志
当节点确认成为 leader 时, 会为每个 follower 启动 replication 对象, 并启动两个协程 replicate 和 heartbeat.
replicate 其内部监听 triggerCh 有无发生通知时, 当有日志需要同步给 follower 调用 replicateTo. 另外 replicate 每次还会创建一个随机 50ms - 100ms 的定时器, 当定时器触发时, 也会尝试同步日志, 主要用来同步 commitIndex 提交索引.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 func (r *Raft) make (chan struct {})defer close (stopHeartbeat)func () false for !shouldStop {select {case maxIndex := <-s.stopCh:case deferErr := <-s.triggerDeferErrorCh:case <-s.triggerCh:case <-randomTimeout(r.config().CommitTimeout):if !shouldStop && s.allowPipeline {goto PIPELINEreturn false if err := r.pipelineReplicate(s); err != nil {if err != ErrPipelineReplicationNotSupported {"failed to start pipeline replication to" , "peer" , peer, "error" , err)goto RPC
replicateTo 用来真正的把日志数据同步给 follower.
首先调用 setupAppendEntries 装载请求同步的日志, 这里需要装载上一条日志及增量日志.
然后使用 transport 给 follower 发送请求, 之后更新状态.
如果装载日志时, 发现 log index 不存在, 则需要发送快照文件.
在发完快照文件后, 需要判断是否继续发送快照点之后的增量日志, 如含有增量则 goto 切到 1.
replicateTo 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 func (r *Raft) uint64 ) (shouldStop bool ) {var req AppendEntriesRequestvar resp AppendEntriesResponsevar start time.Timevar peer Serverif s.failures > 0 {select {case <-time.After(backoff(failureWait, s.failures, maxFailureScale)): case <-r.shutdownCh: if err := r.setupAppendEntries(s, &req, atomic.LoadUint64(&s.nextIndex), lastIndex); err == ErrLogNotFound {goto SEND_SNAPelse if err != nil { return if err := r.trans.AppendEntries(peer.ID, peer.Address, &req, &resp); err != nil {"failed to appendEntries to" , "peer" , peer, "error" , err)return string (peer.ID), start, float32 (len (req.Entries)), r.noLegacyTelemetry)if resp.Term > req.Term {return true if resp.Success {0 true else {-1 , resp.LastLog+1 ), 1 ))if resp.NoRetryBackoff {0 else {"appendEntries rejected, sending older logs" , "peer" , peer, "next" , atomic.LoadUint64(&s.nextIndex))select {case <-s.stopCh: return true default :if atomic.LoadUint64(&s.nextIndex) <= lastIndex {goto STARTreturn if stop, err := r.sendLatestSnapshot(s); stop {return true else if err != nil {"failed to send snapshot to" , "peer" , peer, "error" , err)return goto CHECK_MORE
setupAppendEntries setupAppendEntries 方法会把日志数据和其他元数据装载到 AppendEntriesRequest 对象里.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type AppendEntriesRequest struct {uint64 uint64 uint64 uint64
setupAppendEntries 用来构建 AppendEntriesRequest 对象, 这里不仅当前节点的最新 log 信息, 还有 follower nextIndex 的上一条 log 日志数据, 还有新增的 log 日志数据.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func (r *Raft) uint64 ) error {if err := r.setPreviousLog(req, nextIndex); err != nil {return errif err := r.setNewLogs(req, nextIndex, lastIndex); err != nil {return errreturn nil
setPreviousLog 用来获取 follower 的 nextIndex 的上一条数据, 如果在快照临界点, 则使用快照记录的 index 和 term, 否则其他情况调用 LogStore 存储的 GetLog 获取上一条日志.
需要注意一下, 如果上一条数据的 index 在 logStore 不存在, 那么就需要返回错误, 后面走发送快照逻辑了.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (r *Raft) uint64 ) error {if nextIndex == 1 {0 0 else if (nextIndex - 1 ) == lastSnapIdx {else {var l Logif err := r.logs.GetLog(nextIndex-1 , &l); err != nil {return errreturn nil
setNewLogs 用来获取 nextIndex 到 lastIndex 之间的增量数据, 为避免一次传递太多的数据, 这里限定单次不能超过 MaxAppendEntries 条日志.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 func (r *Raft) uint64 ) error {make ([]*Log, 0 , maxAppendEntries)uint64 (maxAppendEntries)-1 , lastIndex)for i := nextIndex; i <= maxIndex; i++ {new (Log)if err := r.logs.GetLog(i, oldLog); err != nil {return errappend (req.Entries, oldLog)return nil
updateLastAppended updateLastAppended 用来更新记录 follower 的 nextIndex 值, 另外还会调用 commitment.match 改变 commit 记录, 并通知让状态机应用.
每个 follower 在同步完数据后, 都需要调用一次 updateLastAppended, 不仅更新 follower nextIndex, 更重要的是更新 commitIndex 提交索引值, commitment.match 内部检测到 commit 发生变动时, 向 commitCh 提交通知, 最后由 leaderLoop 检测到 commit 通知, 并调用状态机 fsm 应用.
在本地提交后, 当下次 replicate 同步数据时, 自然会携带更新后的 commitIndex, 在 follower 收到且经过判断对比后, 把数据更新自身的状态机里.
1 2 3 4 5 6 7 8 9 10 11 func updateLastAppended(s *followerReplication, req *AppendEntriesRequest) {Mark any inflight logs as committed if logs := req.Entries ; len(logs) > 0 { last := logs[len(logs)-1].StoreUint 64(&s.nextIndex , last.Index +1).commitment .match (s.peer .ID , last.Index ).notifyAll (true)
🔥 重点:
在 leader 里找到绝大数 follower 都满足的 Index 作为 commitIndex 进行提交, 先本地提交, 随着下次 replicate 同步日志时, 通知其他 follower 也提交日志到本地.
计算并提交 commitIndex
match 通过计算各个 server 的 matchIndex 计算出 commitIndex. commitIndex 可以理解为法定的提交索引值. 对所有 server 的 matchIndex 进行排序, 然后使用 matched[(len(matched)-1)/2] 值作为 commitIndex. 这样比 commitIndex 小的 log index 会被推到 commitCh 管道里. 后面由 leaderLoop 进行消费, 然后调用 fsm 状态机进行应用日志.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 func (c *commitment) uint64 ) {defer c.Unlock()if prev, hasVote := c.matchIndexes[server]; hasVote && matchIndex > prev {func (c *commitment) if len (c.matchIndexes) == 0 {return make ([]uint64 , 0 , len (c.matchIndexes))for _, idx := range c.matchIndexes {append (matched, idx)len (matched)-1 )/2 ]if quorumMatchIndex > c.commitIndex && quorumMatchIndex >= c.startIndex {
raft transport 网络层 hashicorp transport 层是使用 msgpack rpc 实现的, 其实现原理没什么可说的.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 func (n *NetworkTransport) error {return n.genericRPC(id, target, rpcAppendEntries, args, resp)func (n *NetworkTransport) uint8 , args interface {}, resp interface {}) error {if err != nil {return errif n.timeout > 0 {if err = sendRPC(conn, rpcType, args); err != nil {return errif canReturn {return err
msgpack rpc 的协议报文格式如下:
follower 处理 appendEntries 日志同步 appendEntries() 是用来处理来自 leader 发起的 appendEntries 请求. 其内部首先判断请求的日志是否可以用, 能用则保存日志到本地**, 然后调用 processLogs 来通知 fsm 状态机应用日志.**
如果请求的上条日志跟本实例最新日志不一致, 则返回失败. 而 leader 会根据 follower 返回结果, 获取 follower 最新的 log term 及 index, 然后再同步给 follower 缺失的日志. 另外当 follower 发现冲突日志时, 也会以 leader 的日志为准来覆盖修复产生冲突的日志.
简单说 appendEntries() 同步日志是 leader 和 follower 不断调整位置再同步数据的过程.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 func (r *Raft) defer metrics.MeasureSince([]string {"raft" , "rpc" , "appendEntries" }, time.Now())false , false , var rpcErr error defer func () if a.Term < r.getCurrentTerm() {return if a.Term > r.getCurrentTerm() || (r.getState() != Follower && !r.candidateFromLeadershipTransfer.Load()) {if len (a.Addr) > 0 {else {if a.PrevLogEntry > 0 { var prevLogTerm uint64 if a.PrevLogEntry == lastIdx {else {var prevLog Logif err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {true return if a.PrevLogTerm != prevLogTerm {true return if len (a.Entries) > 0 {var newEntries []*Log for i, entry := range a.Entries {if entry.Index > lastLogIdx {break var storeEntry Logif err := r.logs.GetLog(entry.Index, &storeEntry); err != nil {return if entry.Term != storeEntry.Term {if err := r.logs.DeleteRange(entry.Index, lastLogIdx); err != nil {return if entry.Index <= r.configurations.latestIndex {break if n := len (newEntries); n > 0 {if err := r.logs.StoreLogs(newEntries); err != nil {return for _, newEntry := range newEntries {if err := r.processConfigurationLogEntry(newEntry); err != nil {return -1 ] if a.LeaderCommitIndex > 0 && a.LeaderCommitIndex > r.getCommitIndex() {if r.configurations.latestIndex <= idx {nil ) true
状态机 FSM 应用日志 不管是 Leader 和 Follower 都会调用状态机 FSM 来应用日志. 其流程是先调用 processLogs 来打包批量日志, 然后将日志推到 fsmMutateCh 管道里, 最后由 runFSM 协程来监听该管道, 并把日志应用到状态机里面.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 func (r *Raft) uint64 , futures map [uint64 ]*logFuture) {if index <= lastApplied {"skipping application of old log" , "index" , index)return func (batch []*commitTuple) select {case r.fsmMutateCh <- batch:case <-r.shutdownCh:for _, cl := range batch {if cl.future != nil {make ([]*commitTuple, 0 , maxAppendEntries)for idx := lastApplied + 1 ; idx <= index; idx++ {var preparedLog *commitTupleif futureOk {else {new (Log)if err := r.logs.GetLog(idx, l); err != nil {"failed to get log" , "index" , idx, "error" , err)panic (err)nil )switch {case preparedLog != nil :append (batch, preparedLog)if len (batch) >= maxAppendEntries {make ([]*commitTuple, 0 , maxAppendEntries)case futureOk:nil )if len (batch) != 0 {
runFSM 主要作用 (Main Purpose):
runFSM 是一个长期运行的 goroutine(协程),它 **专门负责将已提交的日志条目应用到用户提供的有限状态机 (FSM)**。它还负责处理 FSM 的快照创建和恢复操作。异步隔离 开来。这样做可以防止 FSM 的潜在阻塞影响 Raft 内部的及时性和性能,例如心跳、选举、日志复制等关键操作。
runFSM 方法的核心逻辑是一个无限循环,通过 select 监听多个通道,处理不同类型的请求。以下是其主要流程的分解:
初始化和准备
定义 lastIndex 和 lastTerm,用于跟踪状态机已应用的最后一个日志条目的索引和任期。
检查状态机是否支持批处理(BatchingFSM 接口)和配置存储(ConfigurationStore 接口),以决定后续处理方式。
定义核心处理函数
applySingle
:处理单个日志条目。
判断日志类型(LogCommand 或 LogConfiguration),分别调用状态机的 Apply 或 StoreConfiguration 方法。
更新 lastIndex 和 lastTerm。
如果日志条目有关联的 future,则通过 future 返回响应。
applyBatch
:处理一批日志条目。
如果状态机支持批处理(BatchingFSM),则过滤出需要发送的日志条目(仅 LogCommand 和 LogConfiguration 类型),批量调用 ApplyBatch。
如果状态机不支持批处理,则逐个调用 applySingle。
更新 lastIndex 和 lastTerm。
为每个日志条目关联的 future 返回响应。
restore
:从快照恢复状态机。
打开指定的快照文件,读取元数据和内容。
调用状态机的恢复方法(Restore),将快照数据加载到状态机。
更新 lastIndex 和 lastTerm。
通过 future 返回操作结果。
snapshot
:生成状态机快照。
检查是否有新的日志需要快照(如果 lastIndex 为 0,则返回错误)。
调用状态机的 Snapshot 方法生成快照。
通过 future 返回快照对象和操作结果。
主循环监听通道 select 监听以下通道,处理不同的请求:
r.fsmMutateCh
:处理日志应用或状态机恢复请求。
如果收到的是 []*commitTuple,则调用 applyBatch 批量应用日志。
如果收到的是 restoreFuture,则调用 restore 从快照恢复状态机。
r.fsmSnapshotCh
:处理快照生成请求。
r.shutdownCh
:监听 Raft 关闭信号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 func (r *Raft) var lastIndex, lastTerm uint64 func (req *commitTuple) var resp interface {}switch req.log.Type {case LogCommand:case LogConfiguration:func (reqs []*commitTuple) if !batchingEnabled {for _, ct := range reqs {return var lastBatchIndex, lastBatchTerm uint64 make ([]*Log, 0 , len (reqs))for _, req := range reqs {var responses []interface {}if len (sendLogs) > 0 {for _, req := range reqs {if req.future != nil {nil )func (req *restoreFuture) if err != nil {return defer source.Close()if err := fsmRestoreAndMeasure(snapLogger, r.fsm, source, meta.Size); err != nil {return nil )func (req *reqSnapshotFuture) for {select {case ptr := <-r.fsmMutateCh:switch req := ptr.(type ) {case []*commitTuple:case *restoreFuture:default :panic (fmt.Errorf("bad type passed to fsmMutateCh: %#v" , ptr))case req := <-r.fsmSnapshotCh:
二、总结 上述过程简单来说就是, 上层写日志, leader 同步日志, follower 接收日志, leader 确认提交日志, follower 跟着提交日志.
三、问题
问题 1:Raft 如何处理网络分区?
解答:Raft 通过领导人选举和多数派机制来处理网络分区。
分区形成: 当网络分区发生时,集群可能分裂成多个部分,每个部分都无法与多数节点通信。选举: 在每个分区中,如果 Follower 节点在选举超时时间内没有收到 Leader 的心跳,它们会发起选举。多数派: 只有包含多数节点的分区才能选出新的 Leader。少数派分区中的节点无法赢得选举,因为它们无法获得多数票。旧 Leader: 如果旧 Leader 位于少数派分区,它会因为无法与多数节点通信而退位成 Follower。数据一致性: Raft 保证,即使在网络分区的情况下,也只有一个分区能够提交新的日志条目,从而保证数据一致性。分区恢复: 当网络分区恢复后,少数派分区中的节点会重新加入集群,并从新 Leader 那里同步最新的日志。
问题 2:Raft 如何保证数据一致性?
解答:Raft 通过以下机制保证数据一致性:
强领导者: 只有 Leader 才能接受客户端请求并生成新的日志条目。日志复制: Leader 将日志条目复制到所有 Follower。只有当多数 Follower 确认收到日志条目后,Leader 才会提交该条目。仅追加日志: 日志条目只能追加到日志末尾,不能修改或删除。选举限制: 只有拥有最新日志的节点才能成为 Leader。提交限制: 只有 Leader 才能推进 commitIndex,且 commitIndex 只会单调递增。状态机: 所有节点按照相同的顺序应用已提交的日志条目到状态机,保证状态机状态一致。
问题 3:Raft 中的 commitIndex 和 lastApplied 有什么区别?
解答:
commitIndex:commitIndex 的所有日志条目都已安全地复制到多数节点,可以应用到状态机。lastApplied:lastApplied。关系: lastApplied 通常小于或等于 commitIndex。当 lastApplied 小于 commitIndex 时,表示节点正在将已提交的日志条目应用到状态机。当两者相等时,表示状态机是最新的。
问题 4:Raft 如何处理客户端请求的幂等性?
解答:Raft 本身不直接处理客户端请求的幂等性。幂等性通常需要在客户端或应用层实现。一种常见的做法是:
客户端生成唯一 ID: 客户端为每个请求生成一个唯一的 ID(例如 UUID)。服务器跟踪 ID: 服务器跟踪已处理的请求 ID。如果收到具有相同 ID 的重复请求,服务器可以直接返回之前的结果,而无需重新执行操作。状态机: 在应用层,状态机可以记录已执行的请求 ID,以避免重复执行。
四、参考链接 1.Hashicorp Raft实现和API分析
2.hashicorp raft源码学习
3.源码分析 hashicorp raft replication 日志复制的实现原理