
14.Golang 调度器源码分析(二、调度循环、触发调度、线程管理)
Golang 调度器源码分析(二、调度循环、触发调度、线程管理)
注意当前go版本代码为1.23
介绍
关于Golang的协程调度器原理及GMP设计思想可以通过Golang的协程调度器原理及GMP设计思想进行了解,相关基础结构与启动以及创建源码可查看上一篇文章,这一篇文章主要介绍调度器的调度循环实现、触发调度的时机以及线程管理。

调度循环
1 | |
runtime.schedule 函数主要通过runtime.findrunnable 去实现协程的寻找。再调用execute实现执行
runtime.findrunnable 的实现非常复杂,这个 300 多行的函数通过以下的过程获取可运行的 Goroutine:
1 | |
主要步骤流程总结:
- 尝试从本地和全局队列获取 G:
- 全局队列 (公平性): 为了保证公平性,每隔一段时间(
pp.schedtick%61 == 0)且全局队列不为空时,尝试从全局队列获取一个 G。 - 唤醒 finalizer G: 如果finalizer goroutine处于等待唤醒状态, 唤醒它。
- CGO 让出: 如果是cgo环境, 尝试让出cpu给c线程。
- 本地队列: 尝试从当前 P 的本地运行队列获取一个 G。如果获取成功,则直接返回。
- 全局队列: 如果本地队列为空,则尝试从全局运行队列获取一个 G。
- 全局队列 (公平性): 为了保证公平性,每隔一段时间(
- 尝试非阻塞网络轮询 (Netpoll, 优化):
- 如果网络轮询已初始化、有等待者,并且上次轮询时间不为 0,则尝试进行非阻塞网络轮询 (
netpoll(0))。 - 如果轮询到可运行的 G,则将其状态设置为
_Grunnable并返回。
- 如果网络轮询已初始化、有等待者,并且上次轮询时间不为 0,则尝试进行非阻塞网络轮询 (
runtime.runqsteal尝试从其他 P 窃取工作 (Work Stealing):- 如果当前 M 是自旋状态,或者自旋 M 的数量小于限制(繁忙 P 数量的一半),则尝试从其他 P 窃取工作 (
stealWork())。 - 如果窃取成功,则直接返回窃取到的 G。
- 如果窃取失败,但发现了新的工作(例如新的 timer 或 GC 工作),则重新开始查找循环 (
goto top)。
- 如果当前 M 是自旋状态,或者自旋 M 的数量小于限制(繁忙 P 数量的一半),则尝试从其他 P 窃取工作 (
- 尝试运行空闲时间 GC 标记 (Idle-time GC Marking):
- 如果 GC 标记启用、有可用的 GC 标记工作,并且可以添加空闲标记 worker,则尝试从 worker 池中获取一个 worker 并运行。
- 如果获取成功,则将 P 的 GC 标记模式设置为
gcMarkWorkerIdleMode,将 worker goroutine 的状态设置为_Grunnable,并返回该 goroutine。
- WASM 特殊处理:
- 如果回调返回并且没有其他 goroutine 被唤醒,则尝试获取并唤醒事件处理程序 goroutine。
- 准备释放 P 并阻塞:
- 在释放 P 之前,创建
allp、idlepMask和timerpMask的快照,以防止在释放 P 后这些数据被修改。 - 获取全局锁 (
sched.lock)。 - 再次检查 GC 等待和安全点函数。
- 再次检查全局运行队列。
- 再次检查是否需要自旋的M。
- 释放当前 P (
releasep())。 - 将当前 P 放入空闲 P 列表 (
pidleput())。 - 释放全局锁 (
unlock(&sched.lock))。
- 在释放 P 之前,创建
- 处理从自旋到非自旋状态的转换(微妙的舞蹈)
- 如果当前 M 是自旋状态(
mp.spinning),取消自旋状态并减少自旋计数(nmspinning)。 - 为了防止遗漏工作,重新检查以下来源:
- 全局和 P 运行队列
- 如果全局队列不为空,尝试获取空闲 P 并从中获取 goroutine,返回该 goroutine。
- 检查所有 P 的运行队列(
checkRunqsNoP),若找到工作,获取 P 并跳转到top。
- 空闲优先级的 GC 工作
- 检查是否有空闲 GC 工作(
checkIdleGCNoP),若有则获取 P,唤醒相关 goroutine 并返回。
- 检查是否有空闲 GC 工作(
- 定时器
- 检查是否有新创建或到期的定时器(
checkTimersNoP),更新pollUntil。
- 检查是否有新创建或到期的定时器(
- 全局和 P 运行队列
- 如果发现新工作且没有空闲 P,需要恢复自旋状态以确保工作不会丢失。
- 如果当前 M 是自旋状态(
- 轮询网络直到下一个定时器到期
- 如果网络轮询已初始化(
netpollinited),且有等待者或pollUntil != 0,且上次轮询时间非零:- 设置
pollUntil,计算阻塞延迟(delay)。 - 执行阻塞式网络轮询(
netpoll(delay)),获取事件列表。 - 更新时间和轮询状态。
- 如果使用假时间(
faketime != 0)且列表为空,停止 M 并跳转到top。 - 如果获取到空闲 P:
- 从事件列表中获取 goroutine,唤醒并返回。
- 如果列表为空但之前是自旋状态,恢复自旋并跳转到
top。
- 如果未获取到空闲 P,将事件列表注入全局队列,调整等待者计数。
- 设置
- 如果
pollUntil != 0且网络轮询已初始化,检查是否需要中断轮询(netpollBreak)。
- 如果网络轮询已初始化(
- 停止当前 M 并重新开始循环
- 调用
stopm()停止当前 M。 - 跳转到
top重新开始循环,寻找可运行的工作。 - 总而言之,当前函数一定会返回一个可执行的 Goroutine,如果当前不存在就会阻塞等待。
- 调用
接下来由 runtime.execute 执行获取的 Goroutine,做好准备工作后,它会通过 runtime.gogo 将 Goroutine 调度到当前线程上。
1 | |
这里的重点是gogo函数,真正完成了g0到g的切换,切换的实质就是CPU寄存器以及函数调用栈的切换,runtime.gogo 在不同处理器架构上的实现都不同,但是也都大同小异,下面是该函数在 386 架构上的实现:
1 | |
它从 runtime.gobuf 中取出了 runtime.goexit 的程序计数器和待执行函数的程序计数器,其中:
runtime.goexit的程序计数器被放到了栈 SP 上;- 待执行函数的程序计数器被放到了寄存器 BX 上;
Go 语言的调用惯例中正常的函数调用都会使用 CALL 指令,该指令会将调用方的返回地址加入栈寄存器 SP 中,然后跳转到目标函数;当目标函数返回后,会从栈中查找调用的地址并跳转回调用方继续执行剩下的代码。
runtime.gogo 就利用了 Go 语言的调用惯例成功模拟这一调用过程,通过以下几个关键指令模拟 CALL 的过程:
1 | |

图:runtime.gogo 栈内存
上图展示了调用 JMP 指令后的栈中数据,当 Goroutine 中运行的函数返回时,程序会跳转到 runtime.goexit 所在位置执行该函数:
1 | |
经过一系列复杂的函数调用,我们最终在当前线程的 g0 的栈上调用 runtime.goexit0 函数,该函数会将 Goroutine 转换会 _Gdead 状态、清理其中的字段、移除 Goroutine 和线程的关联并调用 runtime.gfput 重新加入处理器的 Goroutine 空闲列表 gFree:
1 | |
在最后 runtime.goexit0 会重新调用 runtime.schedule 触发新一轮的 Goroutine 调度,Go 语言中的运行时调度循环会从 runtime.schedule 开始,最终又回到 runtime.schedule,我们可以认为调度循环永远都不会返回。
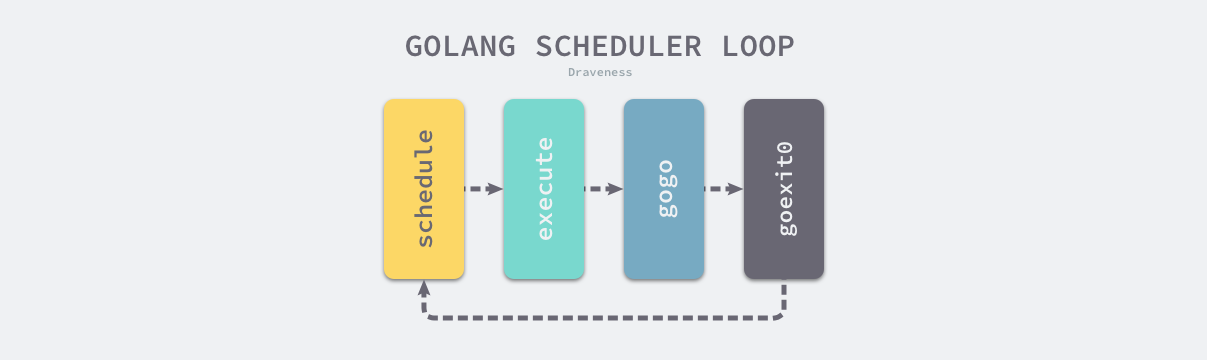
图:调度循环
这里介绍的是 Goroutine 正常执行并退出的逻辑,实际情况会复杂得多,多数情况下 Goroutine 在执行的过程中都会经历协作式或者抢占式调度,它会让出线程的使用权等待调度器的唤醒。
触发调度
这里简单介绍下所有触发调度的时间点,因为调度器的 runtime.schedule 会重新选择 Goroutine 在线程上执行,所以我们只要找到该函数的调用方就能找到所有触发调度的时间点,经过分析和整理,我们能得到如下的树形结构:
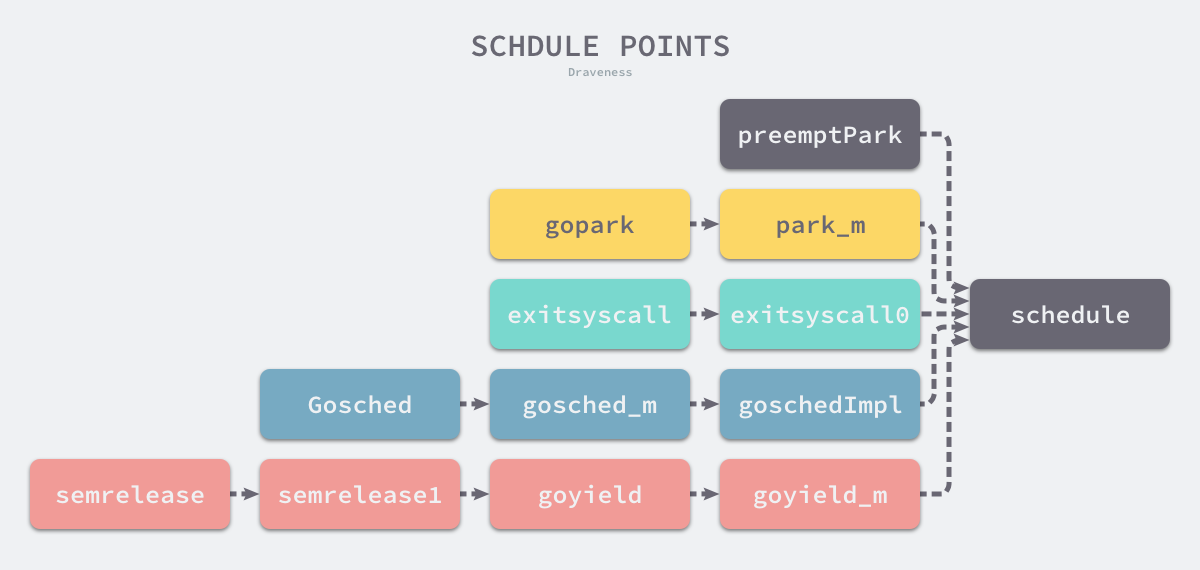
图 调度时间点
除了上图中可能触发调度的时间点,运行时还会在线程启动 runtime.mstart 和 Goroutine 执行结束 runtime.goexit0 触发调度。我们在这里会重点介绍运行时触发调度的几个路径:
- 主动挂起 —
runtime.gopark->runtime.park_m - 系统调用 —
runtime.exitsyscall->runtime.exitsyscall0 - 协作式调度 —
runtime.Gosched->runtime.gosched_m->runtime.goschedImpl - 系统监控 —
runtime.sysmon->runtime.retake->runtime.preemptone
我们在这里介绍的调度时间点不是将线程的运行权直接交给其他任务,而是通过调度器的 runtime.schedule 重新调度。
主动挂起
runtime.gopark 是触发调度最常见的方法,该函数会将当前 Goroutine 暂停,被暂停的任务不会放回运行队列,我们来分析该函数的实现原理:
1 | |
上述会通过 runtime.mcall 切换到 g0 的栈上调用 runtime.park_m:
1 | |
runtime.park_m 会将当前 Goroutine 的状态从 _Grunning 切换至 _Gwaiting,调用 runtime.dropg 移除线程和 Goroutine 之间的关联,在这之后就可以调用 runtime.schedule 触发新一轮的调度了。
当 Goroutine 等待的特定条件满足后,运行时会调用 runtime.goready 将因为调用 runtime.gopark 而陷入休眠的 Goroutine 唤醒。
1 | |
runtime.ready 会将准备就绪的 Goroutine 的状态切换至 _Grunnable 并将其加入处理器的运行队列中,等待调度器的调度。
系统调用
系统调用也会触发运行时调度器的调度,为了处理特殊的系统调用,、在 Goroutine 中加入了 _Gsyscall 状态,Go 语言通过 syscall.Syscall 和 syscall.RawSyscall 等使用汇编语言编写的方法封装操作系统提供的所有系统调用,其中 syscall.Syscall 的实现如下:
1 | |
在通过汇编指令 INVOKE_SYSCALL 执行系统调用前后,上述函数会调用运行时的 runtime.entersyscall 和 runtime.exitsyscall,正是这一层包装能够让我们在陷入系统调用前触发运行时的准备和清理工作。
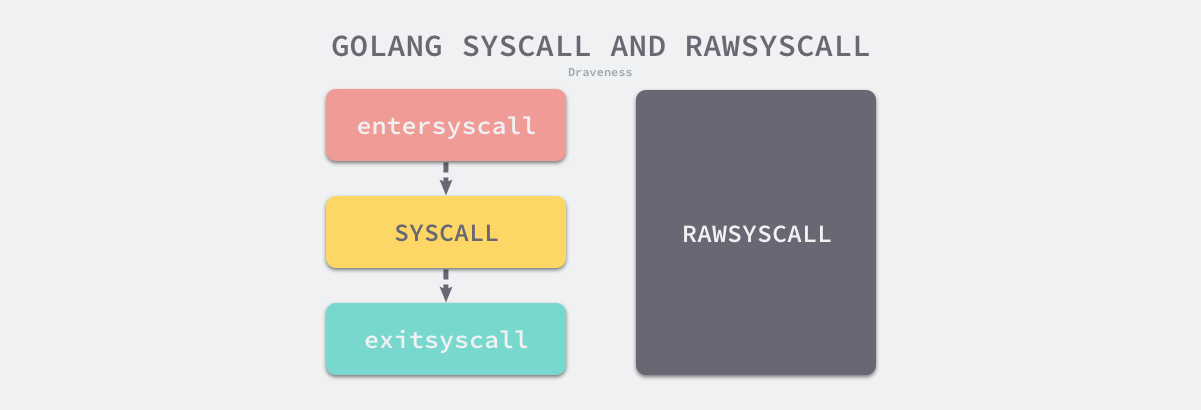
图 语言系统调用
不过出于性能的考虑,如果这次系统调用不需要运行时参与,就会使用 syscall.RawSyscall 简化这一过程,不再调用运行时函数。这里包含 Go 语言对 Linux 386 架构上不同系统调用的分类,我们会按需决定是否需要运行时的参与。
| 系统调用 | 类型 |
|---|---|
| SYS_TIME | RawSyscall |
| SYS_GETTIMEOFDAY | RawSyscall |
| SYS_SETRLIMIT | RawSyscall |
| SYS_GETRLIMIT | RawSyscall |
| SYS_EPOLL_WAIT | Syscall |
| … | … |
表 系统调用的类型
由于直接进行系统调用会阻塞当前的线程,所以只有可以立刻返回的系统调用才可能会被设置成 RawSyscall 类型,例如:SYS_EPOLL_CREATE、SYS_EPOLL_WAIT(超时时间为 0)、SYS_TIME 等。
正常的系统调用过程相对比较复杂,下面将分别介绍进入系统调用前的准备工作和系统调用结束后的收尾工作。
准备工作
runtime.entersyscall 会在获取当前程序计数器和栈位置之后调用 runtime.reentersyscall,它会完成 Goroutine 进入系统调用前的准备工作:
1 | |
- 禁止线程上发生的抢占,防止出现内存不一致的问题;
- 保证当前函数不会触发栈分裂或者增长;
- 保存当前的程序计数器 PC 和栈指针 SP 中的内容;
- 将 Goroutine 的状态更新至
_Gsyscall; - 将 Goroutine 的处理器和线程暂时分离并更新处理器的状态到
_Psyscall; - 释放当前线程上的锁;
需要注意的是 runtime.reentersyscall 会使处理器和线程的分离,当前线程会陷入系统调用等待返回,在锁被释放后,会有其他 Goroutine 抢占处理器资源。
恢复工作
当系统调用结束后,会调用退出系统调用的函数 runtime.exitsyscall 为当前 Goroutine 重新分配资源,该函数有两个不同的执行路径:
- 调用
runtime.exitsyscallfast; - 切换至调度器的 Goroutine 并调用
runtime.exitsyscall0;
1 | |
这两种不同的路径会分别通过不同的方法查找一个用于执行当前 Goroutine 处理器 P,快速路径 runtime.exitsyscallfast 中包含两个不同的分支:
- 如果 Goroutine 的原处理器处于
_Psyscall状态,会直接调用wirep将 Goroutine 与处理器进行关联; - 如果调度器中存在闲置的处理器,会调用
runtime.acquirep使用闲置的处理器处理当前 Goroutine;
另一个相对较慢的路径 runtime.exitsyscall0 会将当前 Goroutine 切换至 _Grunnable 状态,并移除线程 M 和当前 Goroutine 的关联:
- 当我们通过
runtime.pidleget获取到闲置的处理器时就会在该处理器上执行 Goroutine; - 在其它情况下,我们会将当前 Goroutine 放到全局的运行队列中,等待调度器的调度;
无论哪种情况,我们在这个函数中都会调用 runtime.schedule 触发调度器的调度,因为上一节已经介绍过调度器的调度过程,所以在这里就不展开了。
协作式调度
Go 语言基于协作式和信号的两种抢占式调度,这里简单介绍其中的协作式调度。runtime.Gosched 函数会主动让出处理器,允许其他 Goroutine 运行。该函数无法挂起 Goroutine,调度器可能会将当前 Goroutine 调度到其他线程上:
1 | |
经过连续几次跳转,我们最终在 g0 的栈上调用 runtime.goschedImpl,运行时会更新 Goroutine 的状态到 _Grunnable,让出当前的处理器并将 Goroutine 重新放回全局队列,在最后,该函数会调用 runtime.schedule 触发调度。
线程管理
Go 语言既然专门将线程进一步抽象为 Goroutine,自然也就不希望我们对线程做过多的操作,事实也是如此, 大部分的用户代码并不需要线程级的操作。但某些情况下,当需要 使用 cgo 调用 C 端图形库(如 GLib)时,甚至需要将某个 Goroutine 用户态代码一直在主线程上执行。
Go 语言的运行时会通过调度器改变线程的所有权,它也提供了 runtime.LockOSThread 和 runtime.UnlockOSThread 让我们有能力绑定 Goroutine 和线程完成一些比较特殊的操作。
runtime.LockOSThread 会通过如下所示的代码绑定 Goroutine 和当前线程:
1 | |
runtime.dolockOSThread 会分别设置线程的 lockedg 字段和 Goroutine 的 lockedm 字段,这两行代码会绑定线程和 Goroutine。
当 Goroutine 完成了特定的操作之后,会调用以下函数 runtime.UnlockOSThread 分离 Goroutine 和线程:
1 | |
函数执行的过程与 runtime.LockOSThread 正好相反。在多数的服务中,我们都用不到这一对函数,不过使用 CGO 或者经常与操作系统打交道的读者可能会见到它们的身影。
线程生命周期
Go 语言的运行时会通过 runtime.startm 启动线程来执行处理器 P,如果我们在该函数中没能从闲置列表中获取到线程 M 就会调用 runtime.newm 创建新的线程:
1 | |
创建新的线程需要使用如下所示的 runtime.newosproc,该函数在 Linux 平台上会通过系统调用 clone 创建新的操作系统线程,它也是创建线程链路上距离操作系统最近的 Go 语言函数:
1 | |
使用系统调用 clone 创建的线程会在线程主动调用 exit、或者传入的函数 runtime.mstart 返回会主动退出,runtime.mstart 会执行调用 runtime.newm 时传入的匿名函数 fn,到这里也就完成了从线程创建到销毁的整个闭环。
问题
循环调度获取协程主要流程步骤:
- 尝试从本地和全局队列获取 G:
- 全局队列 (公平性): 为了保证公平性,每隔一段时间(
pp.schedtick%61 == 0)且全局队列不为空时,尝试从全局队列获取一个 G。 - 唤醒 finalizer G: 如果finalizer goroutine处于等待唤醒状态, 唤醒它。
- CGO 让出: 如果是cgo环境, 尝试让出cpu给c线程。
- 本地队列: 尝试从当前 P 的本地运行队列获取一个 G。如果获取成功,则直接返回。
- 全局队列: 如果本地队列为空,则尝试从全局运行队列获取一个 G。
- 全局队列 (公平性): 为了保证公平性,每隔一段时间(
- 尝试非阻塞网络轮询 (Netpoll, 优化):
- 如果网络轮询已初始化、有等待者,并且上次轮询时间不为 0,则尝试进行非阻塞网络轮询 (
netpoll(0))。 - 如果轮询到可运行的 G,则将其状态设置为
_Grunnable并返回。
- 如果网络轮询已初始化、有等待者,并且上次轮询时间不为 0,则尝试进行非阻塞网络轮询 (
runtime.runqsteal尝试从其他 P 窃取工作 (Work Stealing):- 如果当前 M 是自旋状态,或者自旋 M 的数量小于限制(繁忙 P 数量的一半),则尝试从其他 P 窃取工作 (
stealWork())。 - 如果窃取成功,则直接返回窃取到的 G。
- 如果窃取失败,但发现了新的工作(例如新的 timer 或 GC 工作),则重新开始查找循环 (
goto top)。
- 如果当前 M 是自旋状态,或者自旋 M 的数量小于限制(繁忙 P 数量的一半),则尝试从其他 P 窃取工作 (
参考链接
1.1.Go 语言设计与实现
1.2理解Go协程调度的本质