
13.Golang 调度器源码分析(一、数据结构、调度器启动与创建协程)
Golang 调度器源码分析(一、数据结构、调度器启动与创建协程)
注意当前go版本代码为1.23
介绍
关于Golang的协程调度器原理及GMP设计思想可以通过Golang的协程调度器原理及GMP设计思想进行了解。
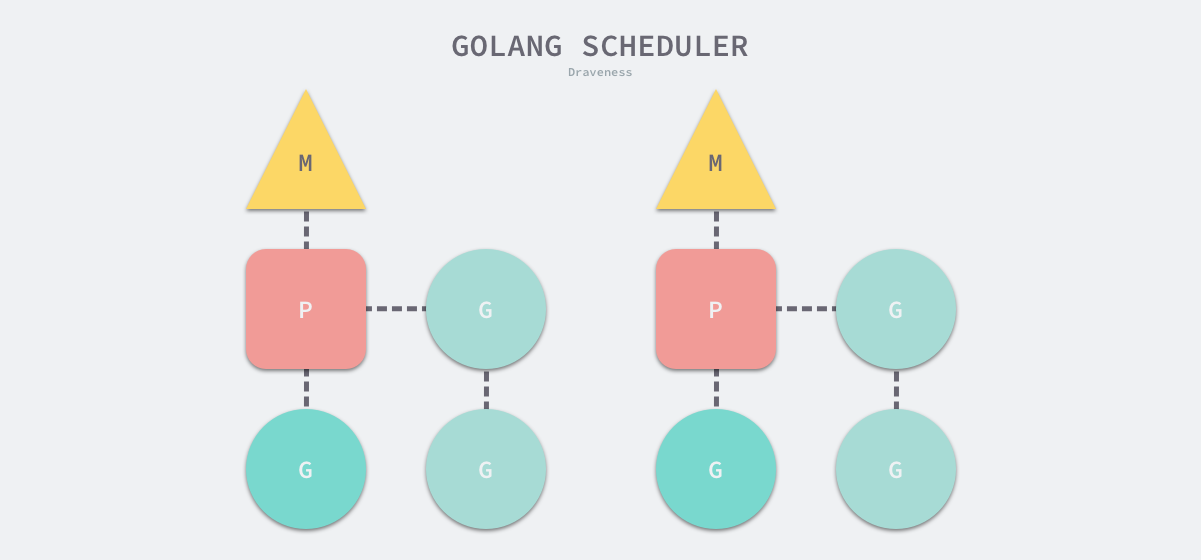
Go 语言调度器三个重要组成部分 — 线程 M、Goroutine G 和处理器 P
- G — 表示 Goroutine,它是一个待执行的任务;
- M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
- P — 表示处理器,它可以被看做运行在线程上的本地调度器;
数据结构
G
1 | |
结构体 runtime.g 的 atomicstatus 字段存储了当前 Goroutine 的状态。除了几个已经不被使用的以及与 GC 相关的状态之外,Goroutine 可能处于以下 9 种状态:
| 状态 | 描述 |
|---|---|
_Gidle |
刚刚被分配并且还没有被初始化 |
_Grunnable |
没有执行代码,没有栈的所有权,存储在运行队列中 |
_Grunning |
可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P |
_Gsyscall |
正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上 |
_Gwaiting |
由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上 |
_Gdead |
没有被使用,没有执行代码,可能有分配的栈 |
_Gcopystack |
栈正在被拷贝,没有执行代码,不在运行队列上 |
_Gpreempted |
由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒 |
_Gscan |
GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在 |
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成三种:等待中、可运行、运行中,运行期间会在这三种状态来回切换:
- 等待中:Goroutine 正在等待某些条件满足,例如:系统调用结束等,包括
_Gwaiting、_Gsyscall和_Gpreempted几个状态; - 可运行:Goroutine 已经准备就绪,可以在线程运行,如果当前程序中有非常多的 Goroutine,每个 Goroutine 就可能会等待更多的时间,即
_Grunnable; - 运行中:Goroutine 正在某个线程上运行,即
_Grunning;
Goroutine 的常见状态迁移
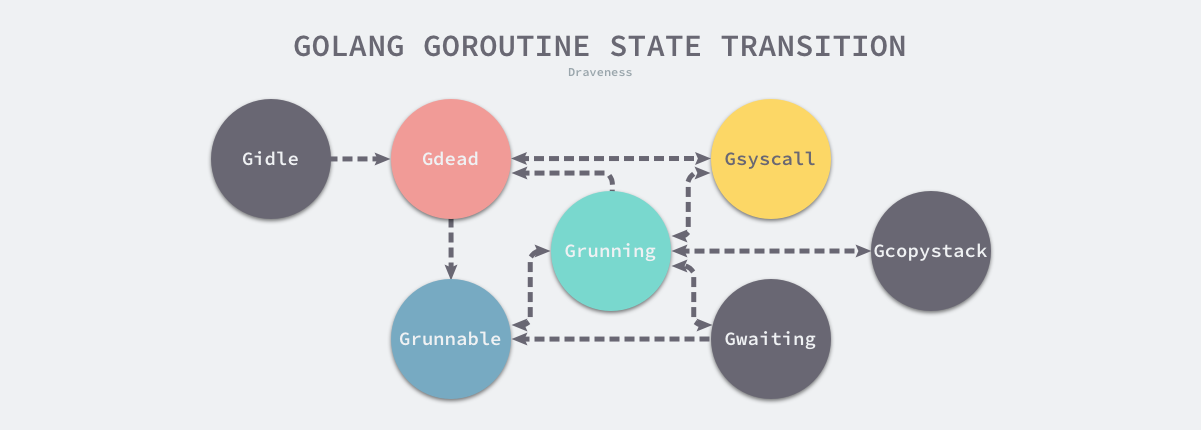
上图展示了 Goroutine 状态迁移的常见路径,其中包括创建 Goroutine 到 Goroutine 被执行、触发系统调用或者抢占式调度器的状态迁移过程。
M
Go 语言并发模型中的 M 是操作系统线程。调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。
在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数,我们也可以在程序中使用 runtime.GOMAXPROCS 来改变最大的活跃线程数。
Go 语言会使用私有结构体 runtime.m 表示操作系统线程,这个结构体包含了几十个字段,这里介绍几个主要的字段:
1 | |
P
调度器中的处理器 P 是线程和 Goroutine 的中间层,它能提供线程需要的上下文环境,也会负责调度线程上的等待队列,通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时让出计算资源,提高线程的利用率。
因为调度器在启动时就会创建 GOMAXPROCS 个处理器,所以 Go 语言程序的处理器数量一定会等于 GOMAXPROCS,这些处理器会绑定到不同的内核线程上。
runtime.p 是处理器的运行时表示,作为调度器的内部实现,它包含的字段也非常多,这里不一样介绍,我们主要关注处理器中的线程和运行队列:
1 | |
反向存储的线程维护着线程与处理器之间的关系,而 runqhead、runqtail 和 runq 三个字段表示处理器持有的运行队列,其中存储着待执行的 Goroutine 列表,runnext 中是线程下一个需要执行的 Goroutine。
runtime.p 结构体中的状态 status 字段会是以下五种中的一种:
| 状态 | 描述 |
|---|---|
_Pidle |
处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
_Prunning |
被线程 M 持有,并且正在执行用户代码或者调度器 |
_Psyscall |
没有执行用户代码,当前线程陷入系统调用 |
_Pgcstop |
被线程 M 持有,当前处理器由于垃圾回收被停止 |
_Pdead |
当前处理器已经不被使用 |
通过分析处理器 P 的状态,我们能够对处理器的工作过程有一些简单理解,例如处理器在执行用户代码时会处于 _Prunning 状态,在当前线程执行 I/O 操作时会陷入 _Psyscall 状态。
调度器启动
调度器的启动过程是我们平时比较难以接触的过程,不过作为程序启动前的准备工作,理解调度器的启动过程对我们理解调度器的实现原理很有帮助,运行时通过 runtime. 初始化调度器:
1 | |
在调度器初始函数执行的过程中会将 maxmcount 设置成 10000,这也就是一个 Go 语言程序能够创建的最大线程数,虽然最多可以创建 10000 个线程,但是可以同时运行的线程还是由 GOMAXPROCS 变量控制。
我们从环境变量 GOMAXPROCS 获取了程序能够同时运行的最大处理器数之后就会调用 runtime.procresize 更新程序中处理器的数量,在这时整个程序不会执行任何用户 Goroutine,调度器也会进入锁定状态,runtime.procresize 的执行过程如下:
- 如果全局变量
allp切片中的处理器数量少于期望数量,会对切片进行扩容; - 使用
new创建新的处理器结构体并调用runtime.p.init初始化刚刚扩容的处理器; - 通过指针将线程 m0 和处理器
allp[0]绑定到一起; - 调用
runtime.p.destroy释放不再使用的处理器结构; - 通过截断改变全局变量
allp的长度保证与期望处理器数量相等; - 将除
allp[0]之外的处理器 P 全部设置成_Pidle并加入到全局的空闲队列中;
调用 runtime.procresize 是调度器启动的最后一步,在这一步过后调度器会完成相应数量处理器的启动,等待用户创建运行新的 Goroutine 并为 Goroutine 调度处理器资源。
创建 Goroutine
想要启动一个新的 Goroutine 来执行任务时,我们需要使用 Go 语言的 go 关键字,编译器会通过 cmd/compile/internal/gc.state.stmt 和 cmd/compile/internal/gc.state.call 两个方法将该关键字转换成 runtime.newproc 函数调用:
1 | |
runtime.newproc1 会根据传入参数初始化一个 g 结构体,我们可以将该函数分成以下几个部分介绍它的实现:
- 获取或者创建新的 Goroutine 结构体;
- 将传入的参数移到 Goroutine 的栈上;
- 更新 Goroutine 调度相关的属性;
首先是 Goroutine 结构体的创建过程:
1 | |
上述代码会先从处理器的 gFree 列表中查找空闲的 Goroutine,如果不存在空闲的 Goroutine,会通过 runtime.malg 创建一个栈大小足够的新结构体。
接下来,调用 runtime.memmove 将 fn 函数的所有参数拷贝到栈上,argp 和 narg 分别是参数的内存空间和大小,我们在该方法中会将参数对应的内存空间整块拷贝到栈上:
1 | |
拷贝了栈上的参数之后,runtime.newproc1 会设置新的 Goroutine 结构体的参数,包括栈指针、程序计数器并更新其状态到 _Grunnable 并返回:
1 | |
上述在分析 runtime.newproc 的过程中,保留了主干省略了用于获取结构体的 runtime.gfget、runtime.malg、将 Goroutine 加入运行队列的 runtime.runqput 以及设置调度信息的过程,下面依次分析这些函数。
初始化结构体
runtime.gfget 通过两种不同的方式获取新的 runtime.g:
- 从 Goroutine 所在处理器的
gFree列表或者调度器的sched.gFree列表中获取runtime.g; - 调用
runtime.malg生成一个新的runtime.g并将结构体追加到全局的 Goroutine 列表allgs中。
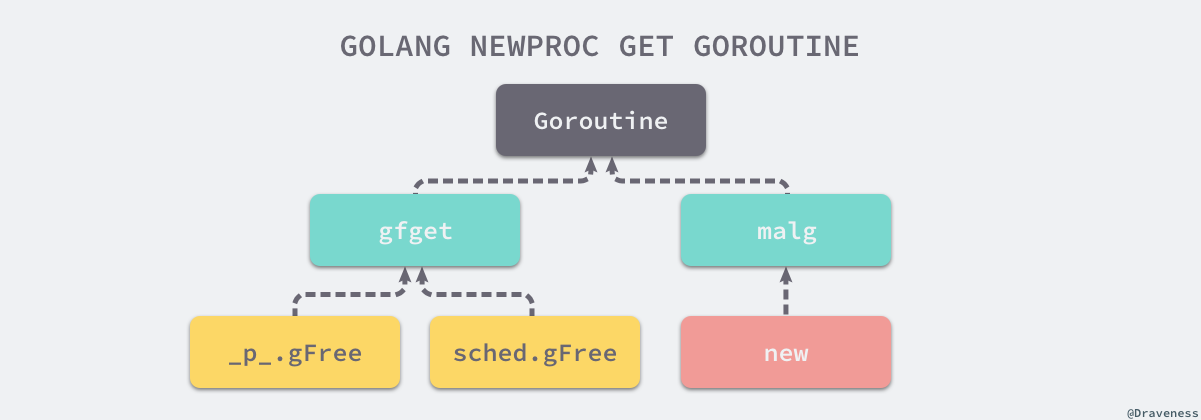
图 获取 Goroutine 结构体的三种方法
runtime.gfget 中包含两部分逻辑,它会根据处理器中 gFree 列表中 Goroutine 的数量做出不同的决策:
- 当处理器的 Goroutine 列表为空时,会将调度器持有的空闲 Goroutine 转移到当前处理器上,直到
gFree列表中的 Goroutine 数量达到 32; - 当处理器的 Goroutine 数量充足时,会从列表头部返回一个新的 Goroutine;
1 | |
当调度器的 gFree 和处理器的 gFree 列表都不存在结构体时,运行时会调用 runtime.malg 初始化新的 runtime.g 结构,如果申请的堆栈大小大于 0,这里会通过 runtime.stackalloc 分配 2KB 的栈空间:
1 | |
runtime.malg 返回的 Goroutine 会存储到全局变量 allgs 中。
简单总结一下,runtime.newproc1 会从处理器或者调度器的缓存中获取新的结构体,也可以调用 runtime.malg 函数创建。
运行队列
runtime.runqput 会将 Goroutine 放到运行队列上,这既可能是全局的运行队列,也可能是处理器本地的运行队列:
1 | |
- 当
next为true时,将 Goroutine 设置到处理器的runnext作为下一个处理器执行的任务; - 当
next为false并且本地运行队列还有剩余空间时,将 Goroutine 加入处理器持有的本地运行队列; - 当处理器的本地运行队列已经没有剩余空间时就会把本地队列中的一部分 Goroutine 和待加入的 Goroutine 通过
runtime.runqputslow添加到调度器持有的全局运行队列上;
处理器本地的运行队列是一个使用数组构成的环形链表,它最多可以存储 256 个待执行任务。
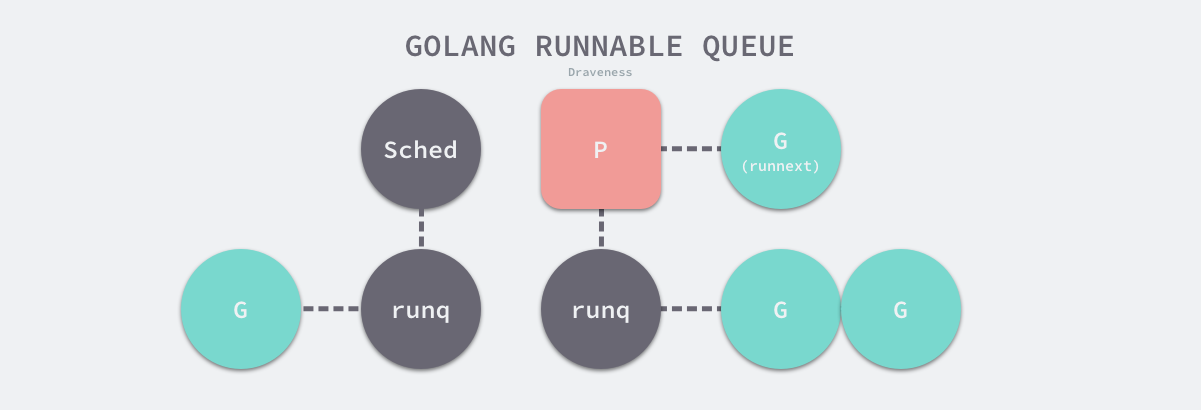
图 全局和本地运行队列
简单总结一下,Go 语言有两个运行队列,其中一个是处理器本地的运行队列,另一个是调度器持有的全局运行队列,只有在本地运行队列没有剩余空间时才会使用全局队列。
调度信息
运行时创建 Goroutine 时会通过下面的代码设置调度相关的信息,前两行代码会分别将程序计数器和 Goroutine 设置成 runtime.goexit 和新创建 Goroutine 运行的函数:
1 | |
上述调度信息 sched 不是初始化后的 Goroutine 的最终结果,它还需要经过 runtime.gostartcallfn 和 runtime.gostartcall 的处理:
1 | |
gostartcall函数的主要作用有两个:
- 调整newg的栈空间,把goexit函数的第二条指令的地址入栈,伪造成goexit函数调用了fn,从而使fn执行完成后执行ret指令时返回到goexit继续执行完成最后的清理工作;
- 重新设置newg.buf.pc 为需要执行的函数的地址,即fn,我们这个场景为runtime.main函数的地址,如果是在运行中go aa()启动的协程,那么newg.buf.pc会为aa()函数的地址。
问题
1.goruntine与thread有什么区别?
核心区别概括:
- 级别: Goroutine 是用户级的轻量级线程,由 Go 语言运行时 (runtime) 管理;Thread 是操作系统级的线程,由操作系统内核 (kernel) 管理。
- 资源消耗: Goroutine 比 thread 更轻量级,资源消耗更少,创建和销毁速度更快。
- 调度: Goroutine 的调度由 Go 运行时负责,采用 M:N 调度模型,将多个 goroutine 调度到少量的 OS 线程上;Thread 的调度由操作系统内核负责,通常是 1:1 调度模型 (每个 thread 对应一个 OS 线程)。
- 上下文切换: Goroutine 的上下文切换比 thread 更快,因为 goroutine 的切换发生在用户态,无需内核参与;Thread 的上下文切换需要内核参与,开销更大。
- 内存占用: Goroutine 的初始栈大小比 thread 更小,且可以动态增长;Thread 的栈大小通常是固定的,占用内存更多。
- 编程模型: Goroutine 与 Go 语言的 channel 机制紧密结合,提供了简洁高效的并发编程模型;Thread 通常需要使用操作系统提供的同步机制 (如锁、信号量) 来进行线程间的通信和同步,编程模型相对复杂。

2.关于Golang的协程调度器原理及GMP设计思想
参考链接
1.1.Go 语言设计与实现
1.2理解Go协程调度的本质