
03.Golang Map源码分析(一、定义与实现原理)
Golang Map源码分析(一、定义与实现原理)
注意当前go版本代码为1.23
在go目录文件命名时我们会经常看见swiss和no_swiss的后缀,在 Go 语言的源码中,
swiss和no_swiss是与 map 实现相关的两种不同的优化策略或机制。它们主要用于处理 map 中键值对的存储和查找优化。以下是它们之间的主要区别:
- Swiss Table(瑞士表)机制
swiss是指瑞士表(Swiss Table)机制,这是一种用于提高哈希表查找效率的优化技术。- 瑞士表是一个复杂的哈希表结构,旨在通过使用一些高级技术(如位操作和稀疏存储)来加速键值对的查找。
- 瑞士表的核心思想是通过一个紧凑的、稀疏的表结构来存储键值对,同时通过位运算快速定位键值对的位置。
- 瑞士表机制通常用于需要高效查找和插入的场景,特别是在键的分布比较稀疏或者冲突较多的情况下。
- No Swiss Table 机制
no_swiss表示不使用瑞士表(no swiss table)机制。- 在
no_swiss情况下,Go 使用更为简单的哈希表结构和算法来处理键值对的存储和查找。- 这种机制通常用于简单的、键的分布比较均匀的场景,或者是当瑞士表优化不能带来显著性能提升时。
- 实现细节
- 在 Go 源码中,
swiss和no_swiss的区别主要体现在 map 的底层实现上。- 使用
swiss机制时,Go 会使用更复杂的哈希表结构和算法。- 使用
no_swiss机制时,Go 会回退到更传统的哈希表实现方式,可能包括简单的数组和链表结构。
- 性能和适用场景
- **瑞士表机制 (
swiss)**:在键的分布不均匀或者冲突较多的情况下,可以显著提高查找效率。适用于大规模、复杂场景下的 map 操作。- **非瑞士表机制 (
no_swiss)**:在键的分布比较均匀且冲突较少的情况下,性能可能与瑞士表相当,但实现更简单,适用于常规场景。
- 源码中的标志
- 在 Go 源码中,
swiss和no_swiss通常通过编译时标志或条件编译来控制。这样可以根据具体的需求和场景选择合适的机制。- 例如,在编译时可以通过条件编译选项来选择使用
swiss或no_swiss机制。
定义
基础结构
Go Map底层采用的是哈希查找表,并使用链表(拉链法)来解决哈希冲突的问题实现了哈希表
1 | |
buckets 是一个指针,最终它指向的是一个结构体:
1 | |
tophash 通常包含此 buckets 中每个键的哈希值的最高字节。 如果 tophash[0] < minTopHash,则 tophash[0] 是一个桶疏散状态。
但这只是表面(src/runtime/map_noswiss.go)的结构,map 在编译时即确定了 map 中 key、value 及桶的大小,因此在运行时仅仅通过指针操作就可以找到特定位置的元素。编译期动态地创建一个新的结构:
1 | |
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
来一个整体的图:
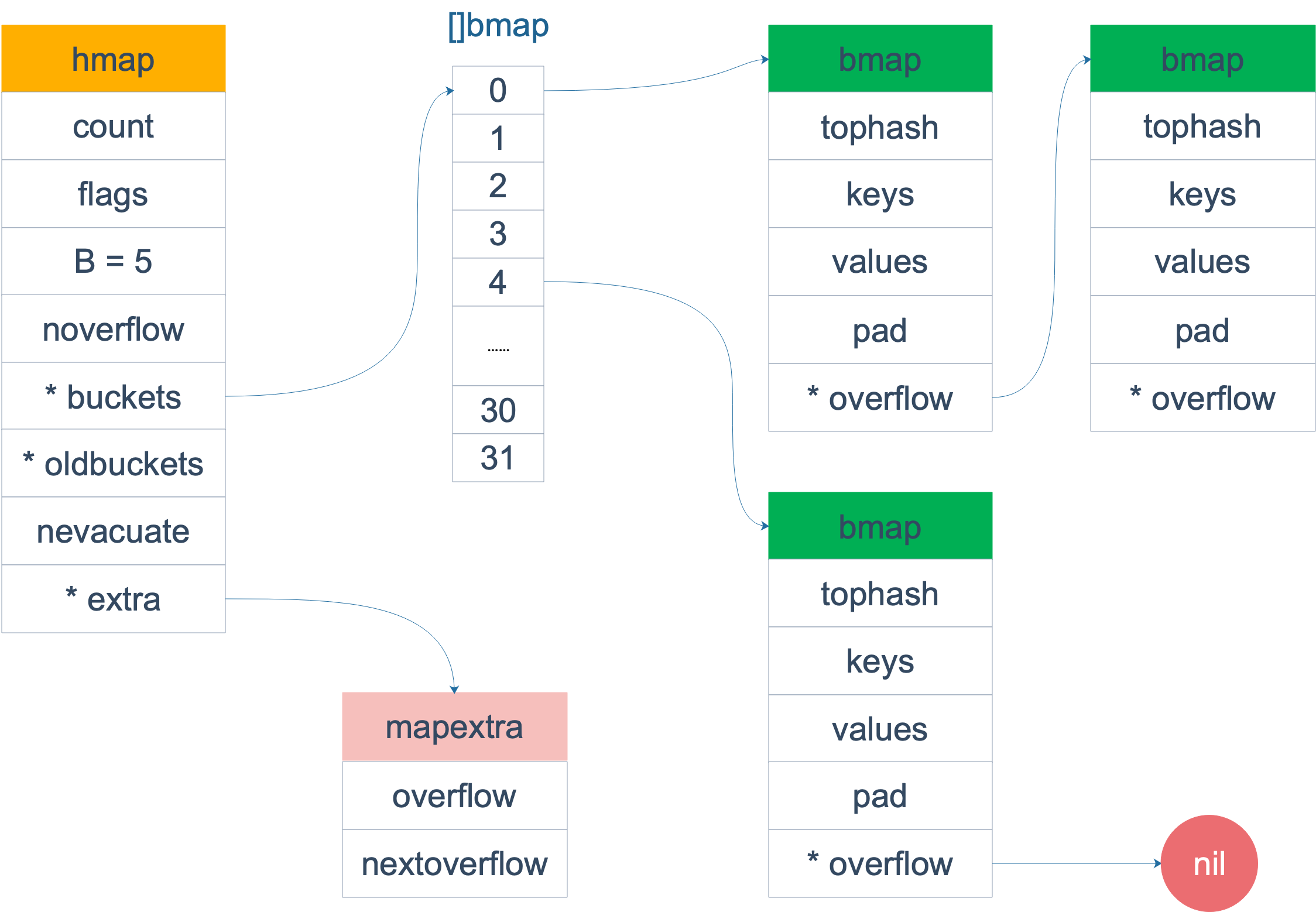
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
1 | |
bmap 是存放 k-v 的地方,我们把视角拉近,仔细看 bmap 的内部组成。

上图就是 bucket 的内存模型,HOB Hash 指的就是 top hash。 注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
例如,有这样一个类型的 map:
1 | |
如果按照 key/value/key/value/... 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 key/key/.../value/value/...,则只需要在最后添加 padding。
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。
哈希函数
map 的一个关键点在于,哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
key 定位过程
key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。还记得前面提到过的 B 吗?如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
1 | |
用最后的 5 个 bit 位,也就是 01010,值为 10,也就是 10 号桶。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的位操作代替。
再用哈希值的高 8 位,找到此 key 在 bucket 中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法:在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
这里参考《Go 程序员面试笔试宝典》里的一张图
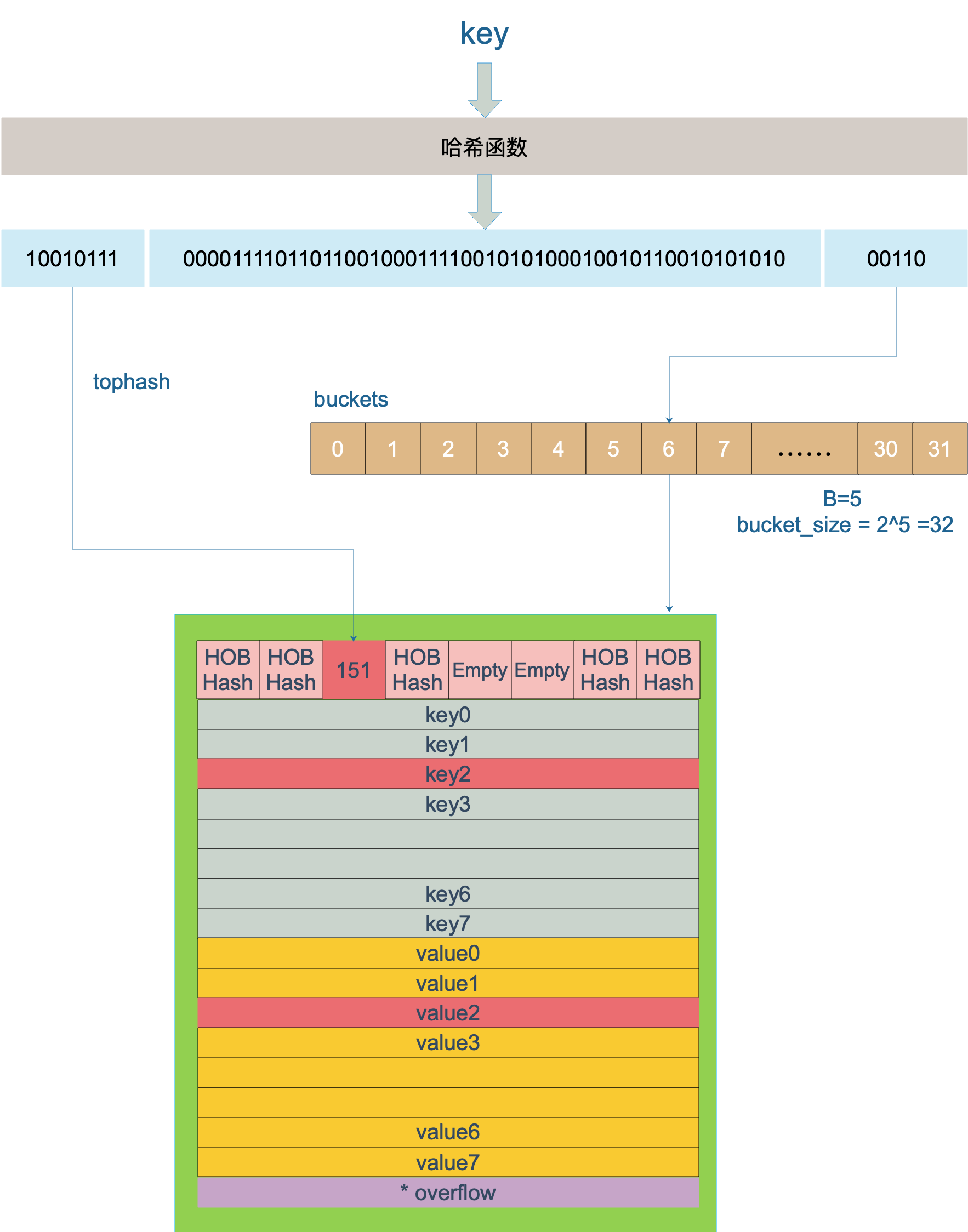
上图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
通过汇编语言可以看到,查找某个 key 的底层函数是 mapaccess 系列函数。这里我们直接看 mapaccess1 函数:
1 | |
基于提供的 mapaccess1 函数源码,我们可以总结 map get 操作的整体过程如下:
1. 安全性和合法性检查:
- 竞争检测: 如果启用了竞争检测(
raceenabled),函数会记录对 map 和 key 的读取操作,以便检测潜在的并发数据竞争。 - 内存清理器检查: 如果启用了内存清理器(如 MSAN 或 ASAN),函数会通知这些工具对 key 的读取操作,以便检查内存安全问题。
- 空 map 或空桶处理: 如果 map 为空(
h == nil)或没有任何元素(h.count == 0),则直接返回零值指针,并可能抛出一个 panic。 - 并发安全检查: 检查 map 的
flags是否指示正在进行写入操作(h.flags&hashWriting != 0)。如果正在写入,则表示存在并发读写冲突,函数会抛出 panic。
2. 查找目标键值对:
- 哈希计算: 使用 map 类型的
Hasher函数计算给定 key 的哈希值(hash := t.Hasher(key, uintptr(h.hash0)))。 - 桶索引计算: 根据哈希值计算桶的索引(
m := bucketMask(h.B)),确定 key 应该存在于哪个桶中。 - 桶地址计算: 根据桶索引计算桶的内存地址(
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize))))。 - 扩容处理: 如果 map 正在进行扩容,则需要检查是否存在旧桶(
c := h.oldbuckets; c != nil)。如果存在旧桶,则根据扩容状态(是否等大小扩容)调整桶索引,并检查旧桶是否已经被迁移。如果旧桶未迁移,则在旧桶中查找。 - 桶遍历和键值匹配:
- 获取哈希值高 8 位: 获取哈希值的高 8 位作为
tophash(top := tophash(hash)),用于快速比较。 - 遍历桶和溢出桶: 遍历目标桶及其溢出桶(
for ; b != nil; b = b.overflow(t))。 - 遍历桶内条目: 遍历桶内的每个条目(
for i := uintptr(0); i < abi.OldMapBucketCount; i++)。 - tophash 比较: 比较条目的
tophash与计算出的tophash是否相等(if b.tophash[i] != top)。如果不相等,则继续下一个条目。如果tophash等于emptyRest,则表示后续桶都为空,退出循环。 - 键地址计算: 如果
tophash匹配,则计算 key 的内存地址(k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))),并根据 key 类型(是否为指针)进行解引用。 - 键值比较: 使用 map 类型的
Equal方法比较计算出的 key 与桶中存储的 key 是否相等(if t.Key.Equal(key, k))。 - 值地址计算: 如果 key 相等,则计算 value 的内存地址(
e := add(unsafe.Pointer(b), dataOffset+abi.OldMapBucketCount*uintptr(t.KeySize)+i*uintptr(t.ValueSize))),并根据 value 类型(是否为指针)进行解引用。 - 返回 value 指针: 返回 value 的指针(
return e)。
- 获取哈希值高 8 位: 获取哈希值的高 8 位作为
3. 未找到 key:
- 如果遍历完所有桶都没有找到匹配的 key,则返回零值指针(
return unsafe.Pointer(&zeroVal[0]))。
简而言之, map get 的过程就是:计算哈希值 -> 定位桶 -> 遍历桶内条目 -> 比较 tophash 和 key -> 返回 value 指针 (或零值指针)。
这里,再看一下定位 key 和 value 的方法以及整个循环的写法。
1 | |
b 是 bmap 的地址,这里 bmap 还是源码里定义的结构体,只包含一个 tophash 数组,经编译器扩充之后的结构体才包含 key,value,overflow 这些字段。dataOffset 是 key 相对于 bmap 起始地址的偏移:
1 | |
因此 bucket 里 key 的起始地址就是 unsafe.Pointer(b)+dataOffset。第 i 个 key 的地址就要在此基础上跨过 i 个 key 的大小;而我们又知道,value 的地址是在所有 key 之后,因此第 i 个 value 的地址还需要加上所有 key 的偏移。理解了这些,上面 key 和 value 的定位公式就很好理解了。
再说整个大循环的写法,最外层是一个无限循环,通过
1 | |
遍历所有的 bucket,这相当于是一个 bucket 链表。
当定位到一个具体的 bucket 时,里层循环就是遍历这个 bucket 里所有的 cell,或者说所有的槽位,也就是 bucketCnt=8 个槽位。整个循环过程:
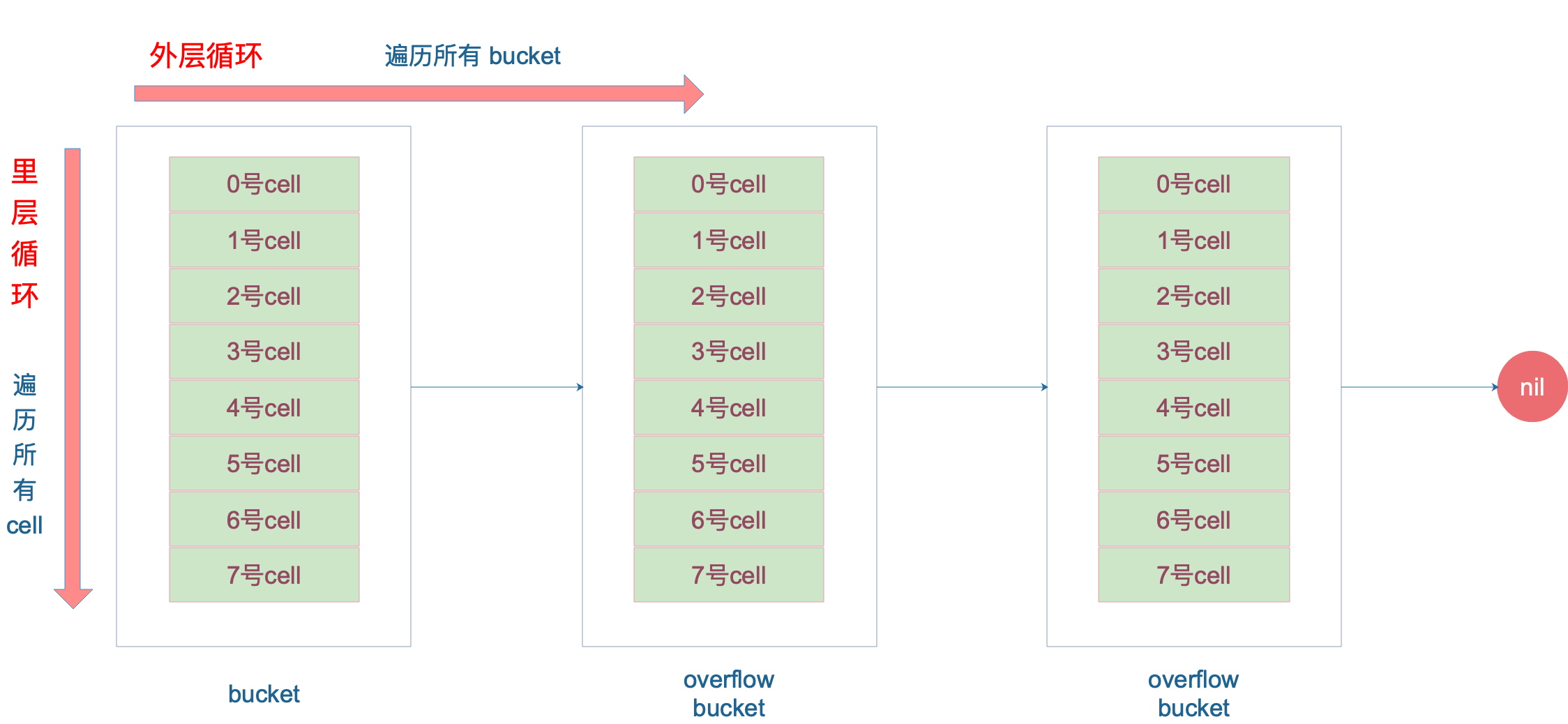
再说一下 minTopHash,当一个 cell 的 tophash 值小于 minTopHash 时,标志这个 cell 的迁移状态。因为这个状态值是放在 tophash 数组里,为了和正常的哈希值区分开,会给 key 计算出来的哈希值一个增量:minTopHash。这样就能区分正常的 top hash 值和表示状态的哈希值。
下面的这几种状态就表征了 bucket 的情况:
1 | |
源码里判断这个 bucket 是否已经搬迁完毕,用到的函数:
1 | |
只取了 tophash 数组的第一个值,判断它是否在 0-5 之间。对比上面的常量,当 top hash 是 evacuatedEmpty、evacuatedX、evacuatedY 这三个值之一,说明此 bucket 中的 key 全部被搬迁到了新 bucket。
问题
1.go中slice 和 map 分别作为函数参数时有什么区别?
在 Go 中,slice 和 map 作为函数参数时,都以引用类型的方式传递。这意味着函数接收到的并非 slice 或 map 的副本,而是指向底层数据的指针。 因此,函数内部对 slice 或 map 的修改会影响到调用者传入的原始数据。 然而,它们之间仍然存在一些关键区别:
1. 数据结构和修改方式的区别:
- Slice: Slice 是一个动态数组的引用,由指向底层数组的指针、长度和容量组成。 当你在函数内部修改 slice 的元素时,修改的是底层数组,因此调用者也能看到这些变化。 然而,如果在函数内部对 slice 进行切片操作或重新分配内存(例如
append超过容量,导致重新分配底层数组),则会创建一个新的底层数组,原 slice 指向的底层数组保持不变。 这时,调用者看到的原始 slice 不会受到影响。 - Map: Map 是一个哈希表的引用。 当你在函数内部修改 map 的键值对时,修改的是原始 map 的内容,调用者也能看到这些变化。 包括添加、修改或删除键值对。 你不需要担心像 slice 那样底层数组重新分配的问题。
2. 内存分配的影响:
- Slice: 如果函数内对 slice 进行 append 操作,并且导致 slice 的容量超过了当前底层数组的容量,Go 会分配一个新的、更大的底层数组,并将原数组的内容复制到新数组中。 这会带来一定的内存分配和复制开销。 如果频繁进行这样的操作,可能会影响性能。
- Map: Map 的扩容机制与 slice 类似,当 map 中的元素数量达到一定阈值时,Go 会重新分配内存并进行 rehash。 但这通常不会像 slice 的 append 操作那样频繁,因为 map 的初始容量和负载因子会影响扩容的频率。
3. nil 值的行为:
- Slice: 将 nil slice 作为参数传递给函数,在函数内部可以对其进行 append 操作,这会创建一个新的底层数组。 函数返回后,调用者将看到一个新的、非 nil 的 slice。
- Map: 将 nil map 作为参数传递给函数,在函数内部直接对其进行赋值或取值操作会导致运行时错误 (panic)。 必须先使用
make函数初始化 map,然后才能进行操作。
1 | |
参考链接
2.《Go学习笔记》