type SelectStmt struct { dmlNode resultSetNode // SelectStmtOpts wraps around select hints and switches. *SelectStmtOpts // Distinct represents whether the select has distinct option. Distinct bool // From is the from clause of the query. From *TableRefsClause // Where is the where clause in select statement. Where ExprNode // Fields is the select expression list. Fields *FieldList // GroupBy is the group by expression list. GroupBy *GroupByClause // Having is the having condition. Having *HavingClause // OrderBy is the ordering expression list. OrderBy *OrderByClause // Limit is the limit clause. Limit *Limit // LockTp is the lock type LockTp SelectLockType // TableHints represents the level Optimizer Hint TableHints [](#)*TableOptimizerHint }
对于本文所提到的语句 SELECT name FROM t WHERE age > 10; name 会被解析为 Fields,WHERE age > 10 被解析为 Where 字段,FROM t 被解析为 From 字段。
Planning
在 planBuilder.buildSelect() 方法中,我们可以看到 ast.SelectStmt 是如何转换成一个 plan 树,最终的结果是一个 LogicalPlan,每一个语法元素都被转换成一个逻辑查询计划单元,例如 WHERE c > 10 会被处理为一个 plan.LogicalSelection 的结构:
1 2 3 4 5 6
if sel.Where != nil { p = b.buildSelection(p, sel.Where, nil) if b.err != nil { returnnil } }
具体的结构如下:
1 2 3 4 5 6 7 8
// LogicalSelection represents a where or having predicate. type LogicalSelection struct { baseLogicalPlan // Originally the WHERE or ON condition is parsed into a single expression, // but after we converted to CNF(Conjunctive normal form), it can be // split into a list of AND conditions. Conditions []expression.Expression }
其中最重要的就是这个 Conditions 字段,代表了 Where 语句需要计算的表达式,这个表达式求值结果为 True 的时候,表明这一行符合条件。
其他字段的 AST 转 LogicalPlan 读者可以自行研究一下,经过这个 buildSelect() 函数后,AST 变成一个 Plan 的树状结构树,下一步会在这个结构上进行优化。
var err error var againRuleList []logicalOptRule // 存储需要再次优化的交互规则
// 遍历逻辑优化规则列表 for i, rule := range optRuleList { // 规则标志的顺序与规则列表中的顺序相同。 // 我们使用位掩码来记录应该使用哪些优化规则。如果第 i 位为 1,则表示我们应该应用第 i 个优化规则。 if flag&(1<<uint(i)) == 0 || isLogicalRuleDisabled(rule) { // 检查是否启用了该规则,以及该规则是否被禁用 continue }
var optRuleList = []logicalOptRule{ &gcSubstituter{}, &columnPruner{}, &resultReorder{}, &buildKeySolver{}, &decorrelateSolver{}, &semiJoinRewriter{}, &aggregationEliminator{}, &skewDistinctAggRewriter{}, &projectionEliminator{}, &maxMinEliminator{}, &constantPropagationSolver{}, &convertOuterToInnerJoin{}, &ppdSolver{}, &outerJoinEliminator{}, &partitionProcessor{}, &collectPredicateColumnsPoint{}, &aggregationPushDownSolver{}, &deriveTopNFromWindow{}, &predicateSimplification{}, &pushDownTopNOptimizer{}, &syncWaitStatsLoadPoint{}, &joinReOrderSolver{}, &columnPruner{}, // column pruning again at last, note it will mess up the results of buildKeySolver &pushDownSequenceSolver{}, &resolveExpand{}, }
这些规则并不会考虑数据的分布,直接无脑的操作 Plan 树,因为大多数规则应用之后,一定会得到更好的 Plan(不过上面有一个规则并不一定会更好,读者可以想一下是哪个)。
这里选一个规则介绍一下,其他优化规则可以自行研究或者是等待后续文章。
columnPruner(列裁剪) 规则,会将不需要的列裁剪掉,考虑这个 SQL: select c from t; 对于 from t 这个全表扫描算子(也可能是索引扫描)来说,只需要对外返回 c 这一列的数据即可,这里就是通过列裁剪这个规则实现,整个 Plan 树从树根到叶子节点递归调用这个规则,每层节点只保留上面节点所需要的列即可。
经过逻辑优化,我们可以得到这样一个查询计划:
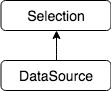
其中 FROM t 变成了 DataSource 算子,WHERE age > 10 变成了 Selection 算子,这里留一个思考题,SELECT name 中的列选择去哪里了?
物理优化
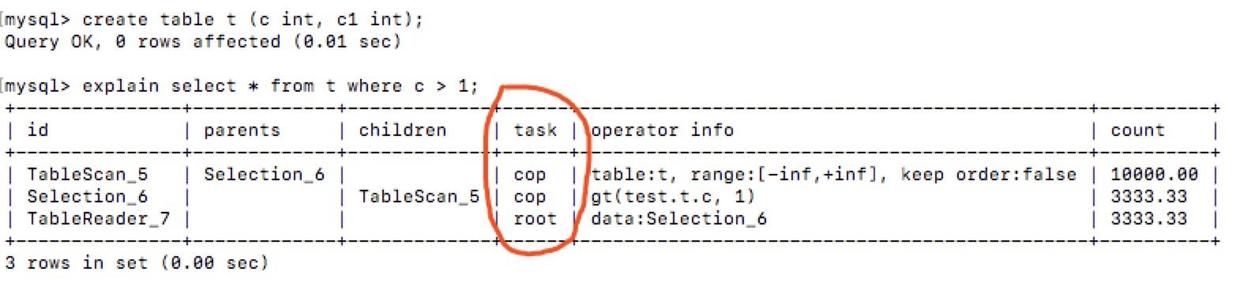
在物理优化阶段,会考虑数据的分布,决定如何选择物理算子,比如对于 FROM t WHERE age > 10 这个语句,假设在 age 字段上有索引,需要考虑是通过 TableScan + Filter 的方式快还是通过 IndexScan 的方式比较快,这个选择取决于统计信息,也就是 age > 10 这个条件究竟能过滤掉多少数据。
// SelectResult is an iterator of coprocessor partial results. type SelectResult interface { // NextRaw gets the next raw result. NextRaw(context.Context) ([]byte, error) // Next reads the data into chunk. Next(context.Context, *chunk.Chunk) error // Close closes the iterator. Close() error } type selectResult struct { label string resp kv.Response
rowLen int fieldTypes []*types.FieldType ctx *dcontext.DistSQLContext
selectResp *tipb.SelectResponse selectRespSize int64// record the selectResp.Size() when it is initialized. respChkIdx int respChunkDecoder *chunk.Decoder
partialCount int64// number of partial results. sqlType string
// copPlanIDs contains all copTasks' planIDs, // which help to collect copTasks' runtime stats. copPlanIDs []int rootPlanID int
stats *selectResultRuntimeStats // distSQLConcurrency and paging are only for collecting information, and they don't affect the process of execution. distSQLConcurrency int paging bool }
selectResult 实现了 SelectResult 这个接口,代表了一次查询的所有结果的抽象,计算是以 Region 为单位进行,所以这里全部结果会包含所有涉及到的 Region 的结果。调用 Chunk 方法可以读到一个 Chunk 的数据,通过不断调用 NextChunk 方法,直到 Chunk 的 NumRows 返回 0 就能拿到所有结果。NextChunk 的实现会不断获取每个 Region 返回的 SelectResponse,把结果写入 Chunk。