Golang 切片(slice)源码分析(一、定义与基础操作实现)
一、定义
slice 的底层数据是数组,slice 是对数组的封装,它描述一个数组的片段。两者都可以通过下标来访问单个元素。
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
数组就是一片连续的内存, slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
1
2
3
4
5
| type slice struct {
array unsafe.Pointer
len int
cap int
}
|
数据结构如下:
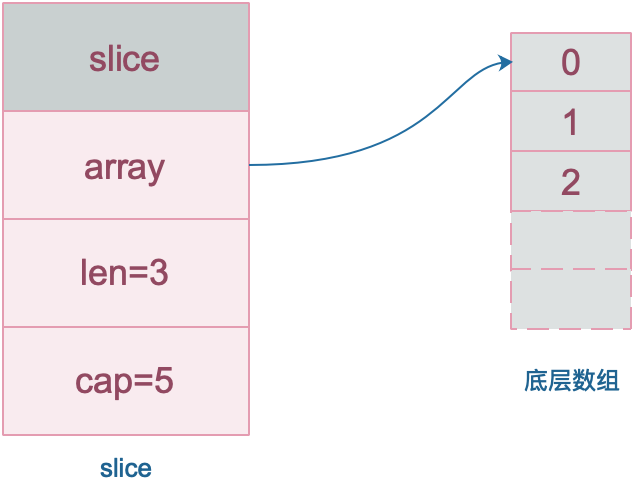
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
二、操作
2.1创建
src/runtime/slice.go 主要逻辑就是基于容量申请内存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
|
2.2扩容
核心源码 growslice-》nextslicecap&&roundupsize
首先通过nextslicecap计算出一个初步的扩容值,通过roundupsize内存对齐得出最终的扩容值,并不是网上的简单公式。
在1.18版本之前,slice源码中nextslicecap扩容主要逻辑为:
当原 slice 容量小于 1024 的时候,新 slice 容量变成原来的 2 倍;原 slice 容量超过 1024,新 slice 容量变成原来的1.25倍。
在1.18版本更新之后,slice源码中nextslicecap的扩容主要逻辑变为了:
当原slice容量(oldcap)小于256的时候,新slice(newcap)容量为原来的2倍;原slice容量超过256,新slice容量newcap = oldcap+(oldcap+3*256)/4
下述为go1.23源码逻辑src/runtime/slice.go :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
|
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := nextslicecap(newLen, oldCap)
var overflow bool
var lenmem, newlenmem, capmem uintptr
noscan := !et.Pointers()
switch {
case et.Size_ == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap), noscan)
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.Size_ == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap)*goarch.PtrSize, noscan)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.Size_):
var shift uintptr
if goarch.PtrSize == 8 {
shift = uintptr(sys.TrailingZeros64(uint64(et.Size_))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.Size_))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap)<<shift, noscan)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem, noscan)
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
}
核心代码:
func nextslicecap(newLen, oldCap int) int {
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
return newLen
}
const threshold = 256
if oldCap < threshold {
return doublecap
}
for {
newcap += (newcap + 3*threshold) >> 2
if uint(newcap) >= uint(newLen) {
break
}
}
if newcap <= 0 {
return newLen
}
return newcap
}
func roundupsize(size uintptr, noscan bool) (reqSize uintptr) {
reqSize = size
if reqSize <= maxSmallSize-mallocHeaderSize {
if !noscan && reqSize > minSizeForMallocHeader {
reqSize += mallocHeaderSize
}
if reqSize <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(reqSize, smallSizeDiv)]]) - (reqSize - size)
}
return uintptr(class_to_size[size_to_class128[divRoundUp(reqSize-smallSizeMax, largeSizeDiv)]]) - (reqSize - size)
}
reqSize += pageSize - 1
if reqSize < size {
return size
}
return reqSize &^ (pageSize - 1)
}
|
三、测试
【引申1】 [3]int 和 [4]int 是同一个类型吗?
不是。因为数组的长度是类型的一部分,这是与 slice 不同的一点。
【引申2】 下面的代码输出是什么?
说明:例子来自雨痕大佬《Go学习笔记》第四版,P43页。这里我会进行扩展,并会作图详细分析。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| package main
import "fmt"
func main() {
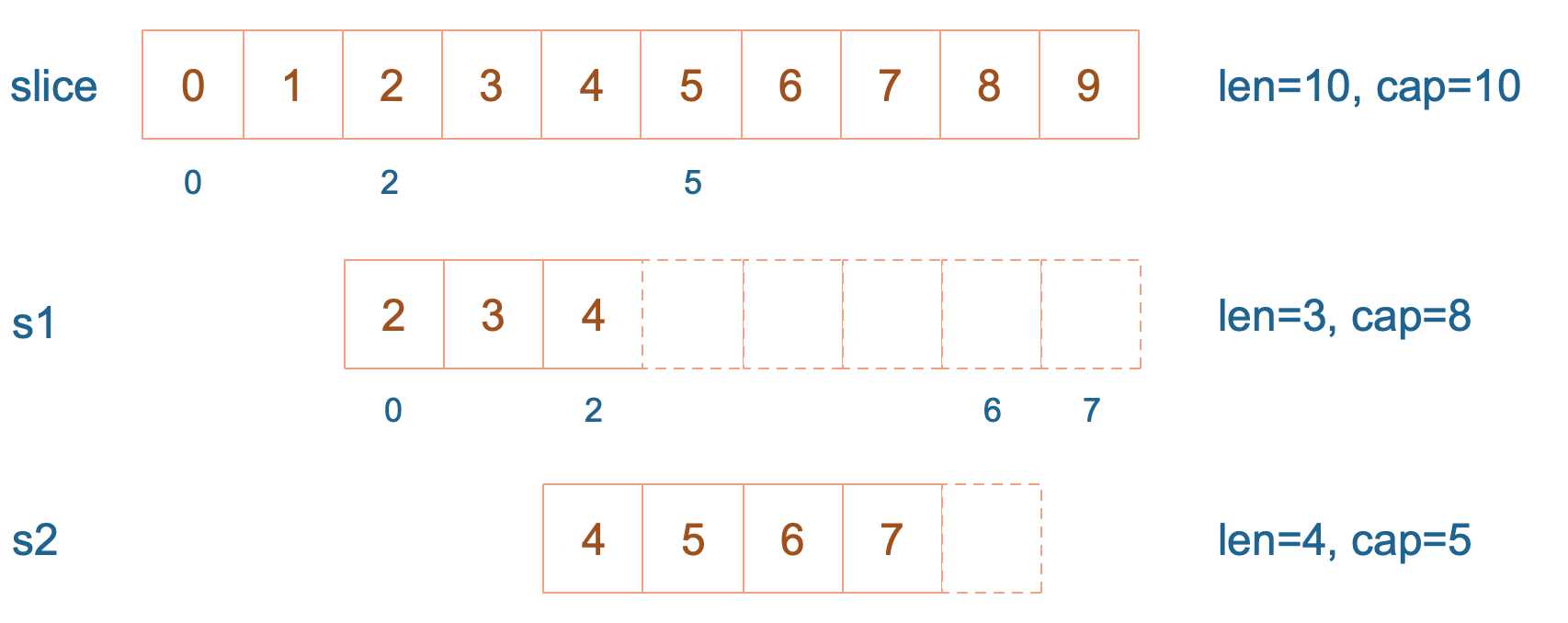
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:6:7]
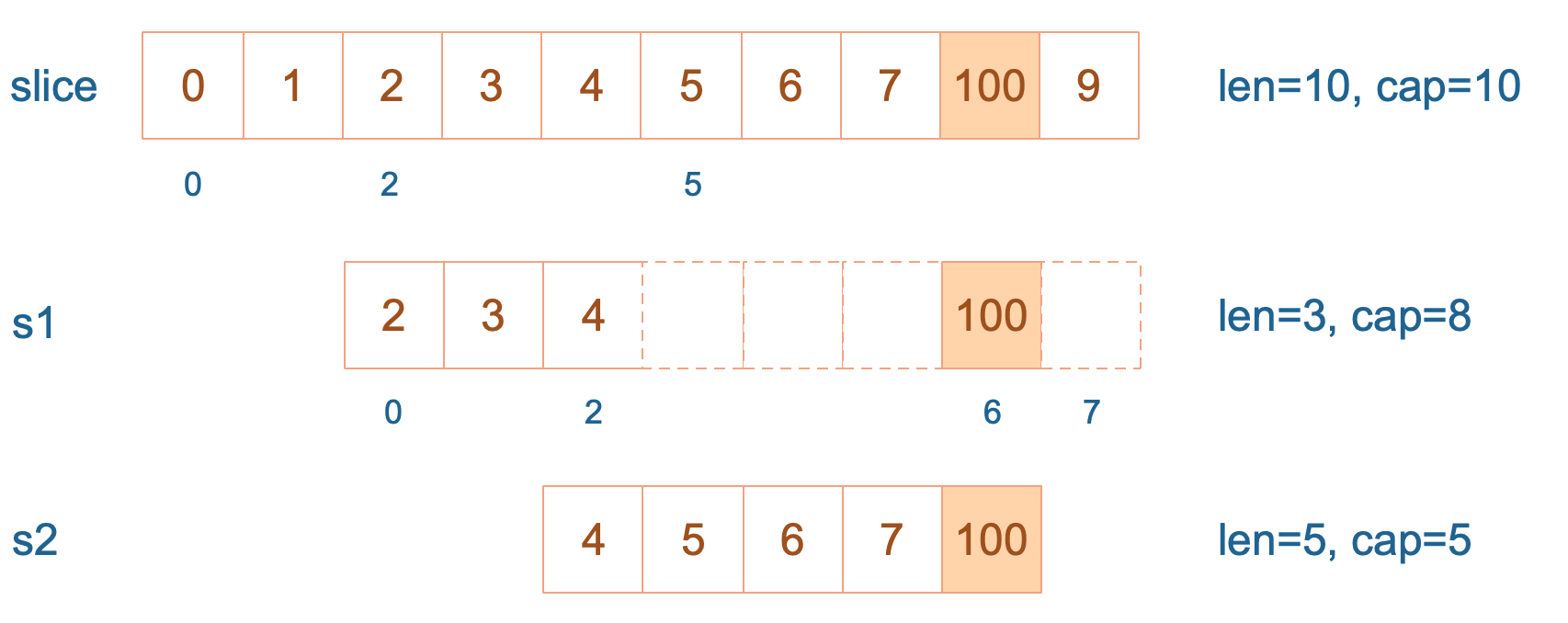
s2 = append(s2, 100)
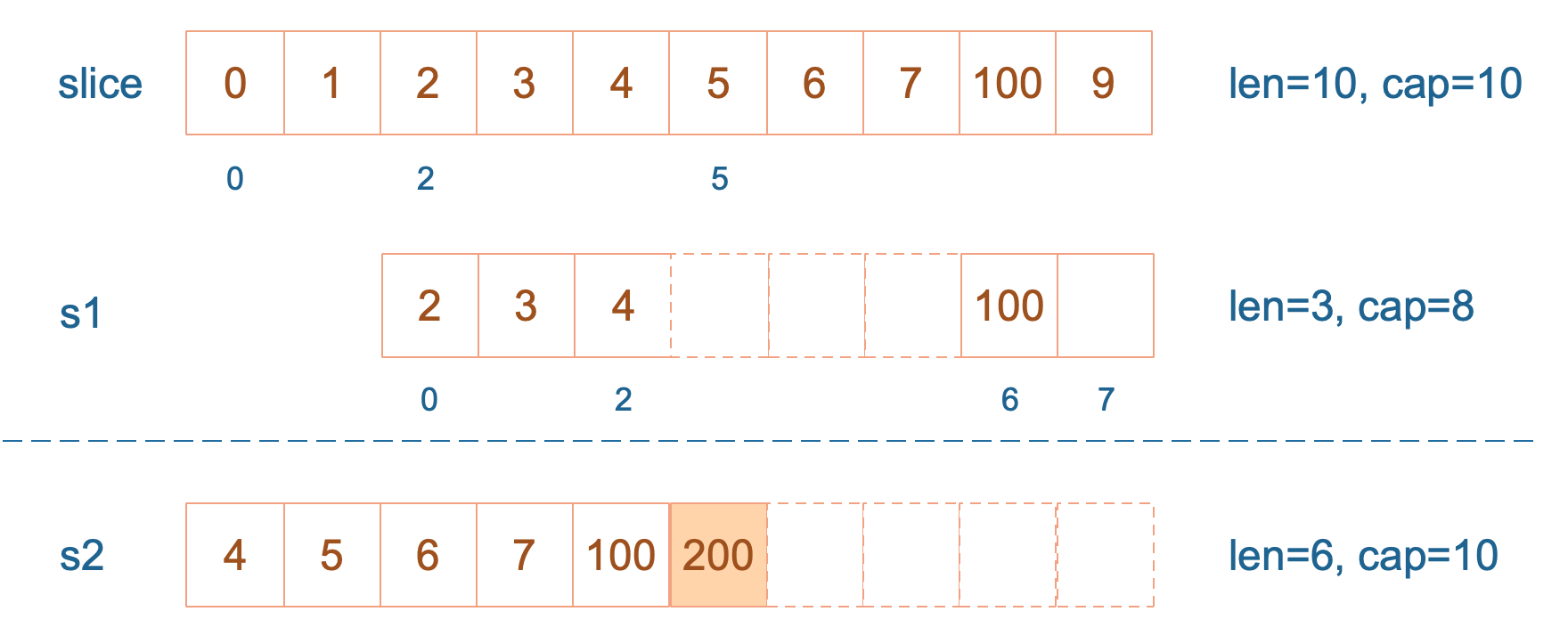
s2 = append(s2, 200)
s1[2] = 20
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(slice)
}
|
结果:
1
2
3
| [2 3 20]
[4 5 6 7 100 200]
[0 1 2 3 20 5 6 7 100 9]
|
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。
接着,向 s2 尾部追加一个元素 100:
s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
再次向 s2 追加元素200:
这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。
最后,修改 s1 索引为2位置的元素:
这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。
![s1[2]=20](https://golang.design/go-questions/slice/assets/4.png)
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
参考链接
1.Go 程序员面试笔试宝典
2.Go学习笔记
3.golangSlice的扩容规则
