
04.TiDB Insert 语句执行流程
四、TiDB Insert 语句执行流程
主要内容转载自 TiDB 源码阅读系列文章(四)Insert 语句概览
本文为 TiDB 源码阅读系列文章的第四篇。上一篇文章简单介绍了整体流程,无论什么语句,大体上是在这个框架下运行,DDL 语句也不例外。
本篇文章会以 Insert 语句为例进行讲解,帮助读者理解前一篇文章。
表结构
这里先给一个表结构,下面介绍的 SQL 语句都是在这个表上的操作。
1 | |
Insert 语句
INSERT INTO t VALUES ("pingcap001", "pingcap", 3); 以这条语句为例,解释 Insert 是如何运行的。
语句处理流程
首先大家回忆一下上一篇文章介绍的框架,一条 SQL 语句经过协议层、Parser、Plan、Executor 这样几个模块处理后,变成可执行的结构,再通过 Next() 来驱动语句的真正执行。对于框架,每类语句都差不多;对于每个核心步骤,每个语句会有自己的处理逻辑。
语法解析
先看 Parser,对于 Insert 语句的解析逻辑,可以看到这条语句会被解析成下面这个结构:
1 | |
这里提到的语句比较简单,只会涉及 Table 以及 Lists 这两个字段,也就是向哪个表插入哪些数据。其中 Lists 是一个二维数组,数组中的每一行对应于一行数据,这个语句只包含一行数据。有了 AST 之后,需要对其进行一系列处理,预处理、合法性验证、权限检查这些暂时跳过(每个语句的处理逻辑都差不多),我们看一下针对 Insert 语句的处理逻辑。
查询计划
接下来是将 AST 转成 Plan 结构,这个操作是在 planBuilder.buildInsert() 中完成。对于这个简单的语句,主要涉及两个部分:
补全 Schema 信息
包括 Database/Table/Column 信息,这个语句没有指定向哪些列插入数据,所以会使用所有的列。
处理 Lists 中的数据
这里会处理一遍所有的 Value,将 ast.ExprNode 转换成 expression.Expression,也就是纳入了我们的表达式框架,后面会在这个框架下求值。大多数情况下,这里的 Value 都是常量,也就是 expression.Constant。
如果 Insert 语句比较复杂,比如要插入的数据来自于一个 Select,或者是 OnDuplicateUpdate 这种情况,还会做更多的处理,这里暂时不再深入描述,读者可以执行看 buildInsert() 中其他的代码。
现在 ast.InsertStmt 已经被转换成为 plan.Insert 结构,对于 Insert 语句并没有什么可以优化的地方,plan.Insert 这个结构只实现了 Plan 这个接口,所以在下面这个判断中,不会走进 Optimize 流程:
1 | |
其他比较简单的语句也不会进入 doOptimize,比如 Show 这种语句,下一篇文章会讲解 Select 语句,会涉及到 doOptimize 函数。
执行
拿到 plan.Insert 这个结构后,查询计划就算制定完成。最后我们看一下 Insert 是如何执行的。
首先 plan.Insert 在这里被转成 executor.InsertExec 结构,后续的执行都由这个结构进行。执行入口是 Next 方法,第一步是要对待插入数据的每行进行表达式求值,具体的可以看 getRows 这个函数,拿到数据后就进入最重要的逻辑— InsertExec.exec() 这个函数,这个函数有点长,不过只考虑我们文章中讲述的这条 SQL 的话,可以把代码简化成下面这段逻辑:
1 | |
接下来我们看一下 AddRecord 这个函数是如何将一行数据写入存储引擎中。要理解这段代码,需要了解一下 TiDB 是如何将 SQL 的数据映射为 Key-Value,可以先读一下我们之前写的一些文章,比如三篇文章了解 TiDB 技术内幕 - 说计算。这里假设读者已经了解了这一点背景知识,那么一定会知道这里需要将 Row 和 Index 的 Key-Value 构造出来的,写入存储引擎。
构造 Index 数据的代码在 addIndices() 函数中,会调用 index.Create() 这个方法:
1 | |
1 | |
构造 Row 数据的代码比较简单,就在 tables.AddRecord 函数中:
1 | |
1 | |
构造完成后,调用类似下面这段代码即可将 Key-Value 写到当前事务的缓存中:
1 | |
在事务的提交过程中,即可将这些 Key-Value 提交到存储引擎中。
核心流程代码
1 | |
1.addRecordWithAutoIDHint 位置:pkg/executor/insert_common.go
1 | |
2.AddRecord 位置: pkg/table/tables/tables.go(只展示主要代码注释可查看:https://github.com/longpi1/tidb/blob/chinese_annotation/pkg/table/table.go)
1 | |
3.索引创建Create位置:pkg/table/tables/index.go
1 | |
小结
Insert 语句在诸多 DML 语句中算是最简单的语句,本文也没有涉及 Insert 语句中更复杂的情况,所以相对比较好理解。上面讲了这么多代码,让我们用一幅图来再回顾一下整个流程。
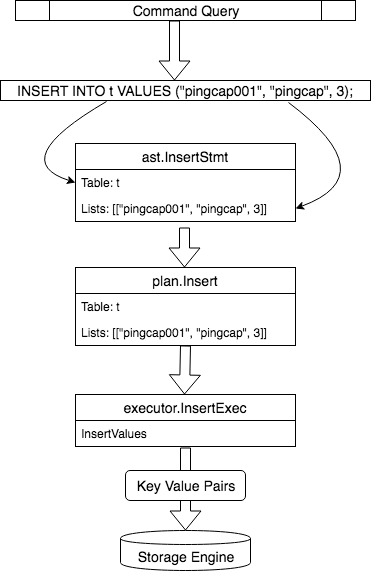
流程图