type SelectStmt struct { dmlNode resultSetNode // SelectStmtOpts wraps around select hints and switches. *SelectStmtOpts // Distinct represents whether the select has distinct option. Distinct bool // From is the from clause of the query. From *TableRefsClause // Where is the where clause in select statement. Where ExprNode // Fields is the select expression list. Fields *FieldList // GroupBy is the group by expression list. GroupBy *GroupByClause // Having is the having condition. Having *HavingClause // OrderBy is the ordering expression list. OrderBy *OrderByClause // Limit is the limit clause. Limit *Limit // LockTp is the lock type LockTp SelectLockType // TableHints represents the level Optimizer Hint TableHints []*TableOptimizerHint }
其中,FROM t 会被解析为 FROM 字段,WHERE c > 1 被解析为 Where 字段,* 被解析为 Fields 字段。所有的语句的结构够都被抽象为一个 ast.StmtNode,这个接口读者可以自行看注释,了解一下。这里只提一点,大部分 ast 包中的数据结构,都实现了 ast.Node 接口,这个接口有一个 Accept 方法,后续对 AST 的处理,主要依赖这个 Accept 方法,以 Visitor 模式遍历所有的节点以及对 AST 做结构转换。
// RecordSet is an abstract result set interface to help get data from Plan. type RecordSet interface { // Fields gets result fields. Fields() []*ResultField // Next returns the next row, nil row means there is no more to return. Next(ctx context.Context) (row types.Row, err error) // NextChunk reads records into chunk. NextChunk(ctx context.Context, chk *chunk.Chunk) error // NewChunk creates a new chunk with initial capacity. NewChunk() *chunk.Chunk // SupportChunk check if the RecordSet supports Chunk structure. SupportChunk() bool // Close closes the underlying iterator, call Next after Close will // restart the iteration. Close() error }
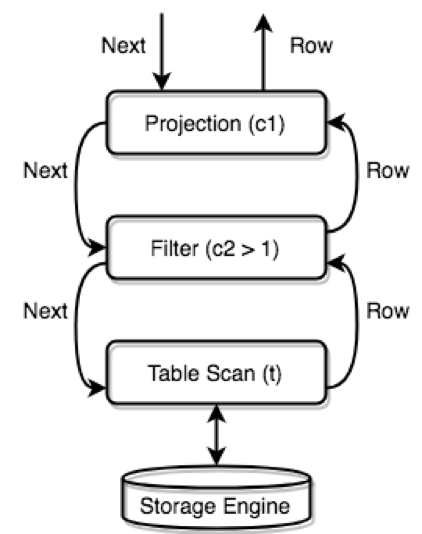
TiDB 的执行引擎是以 Volcano 模型运行,所有的物理 Executor 构成一个树状结构,每一层通过调用下一层的 Next/NextChunk() 方法获取结果。 举个例子,假设语句是 SELECT c1 FROM t WHERE c2 > 1;,并且查询计划选择的是全表扫描+过滤,那么执行器树会是下面这样:
执行器树
大家可以从图中看到 Executor 之间的调用关系,以及数据的流动方式。那么最上层的 Next 是在哪里调用,也就是整个计算的起始点在哪里,谁来驱动这个流程? 有两个地方大家需要关注,这两个地方分别处理两类语句。 第一类语句是 Select 这种查询语句,需要对客户端返回结果,这类语句的执行器调用点在给客户端返回数据的地方:
1
row, err = rs.Next(ctx)
这里的 rs 即为一个 RecordSet 接口,对其不断的调用 Next(),拿到更多结果,返回给 MySQL Client。 第二类语句是 Insert 这种不需要返回数据的语句,只需要把语句执行完成即可。这类语句也是通过 Next 驱动执行,驱动点在构造 recordSet 结构之前:
1 2 3 4 5 6 7 8 9
// If the executor doesn't return any result to the client, we execute it without delay. if e.Schema().Len() == 0 { return a.handleNoDelayExecutor(goCtx, e, ctx, pi) } else if proj, ok := e.(*ProjectionExec); ok && proj.calculateNoDelay { // Currently this is only for the "DO" statement. Take "DO 1, @a=2;" as an example: // the Projection has two expressions and two columns in the schema, but we should // not return the result of the two expressions. return a.handleNoDelayExecutor(goCtx, e, ctx, pi) }