import torch from PIL import Image from IPython.display import display from IPython.display import Image as IPyImage from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32") processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
cat_text = "This is a cat." cat_text_tensor = get_text_feature(cat_text)
dog_text = "This is a dog." dog_text_tensor = get_text_feature(dog_text)
display(IPyImage(filename='./data/cat.jpg'))
print("Similarity with cat : ", cosine_similarity(image_tensor, cat_text_tensor)) print("Similarity with dog : ", cosine_similarity(image_tensor, dog_text_tensor))
输出结果:
1 2 3
Similarity with cat : tensor([0.2482]) Similarity with dog : tensor([0.2080])
最后,我们就可以利用上面的这些函数,来计算图片和文本之间的相似度了。我们拿了一张程序员们最喜欢的猫咪照片,和“This is a cat.” 以及 “This is a dog.” 的文本做比较。可以看到,结果的确是猫咪照片和“This is a cat.” 的相似度要更高一些。
我们可以再多拿一些文本来进行比较。图片里面,实际是2只猫咪在沙发上,那么我们分别试试”There are two cats.”、”This is a couch.”以及一个完全不相关的“This is a truck.”,看看效果怎么样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
two_cats_text = "There are two cats." two_cats_text_tensor = get_text_feature(two_cats_text)
truck_text = "This is a truck." truck_text_tensor = get_text_feature(truck_text)
couch_text = "This is a couch." couch_text_tensor = get_text_feature(couch_text)
print("Similarity with cat : ", cosine_similarity(image_tensor, cat_text_tensor)) print("Similarity with dog : ", cosine_similarity(image_tensor, dog_text_tensor)) print("Similarity with two cats : ", cosine_similarity(image_tensor, two_cats_text_tensor)) print("Similarity with truck : ", cosine_similarity(image_tensor, truck_text_tensor)) print("Similarity with couch : ", cosine_similarity(image_tensor, couch_text_tensor))
输出结果:
1 2 3 4 5 6
Similarity with cat : tensor([0.2482]) Similarity with dog : tensor([0.2080]) Similarity with two cats : tensor([0.2723]) Similarity with truck : tensor([0.1814]) Similarity with couch : tensor([0.2376])
可以看到,“There are two cats.” 的相似度最高,因为图里有沙发,所以“This is a couch.”的相似度也要高于“This is a dog.”。而Dog好歹和Cat同属于宠物,相似度也比完全不相关的Truck要高一些。可以看到,CLIP模型对图片和文本的语义理解是非常到位的。
for i inrange(len(categories)): print(f"{categories[i]}\t{probs[0][i].item():.2%}")
输出结果:
1 2 3 4 5
cat 74.51% dog 0.39% truck 0.04% couch 25.07%
代码非常简单,我们还是先加载model和processor。不过这一次,我们不再是通过计算余弦相似度来进行分类了。而是直接通过一个分类的名称,用softmax算法来计算图片应该分类到具体某一个类的名称的概率。在这里,我们给所有名称都加上了一个“a photo of a ”的前缀。这是为了让文本数据更接近CLIP模型拿来训练的输入数据,因为大部分采集到的图片相关的alt和title信息都不大可能会是一个单词,而是一句完整的描述。
# Read the image image_path = "./data/cat.jpg" image = cv2.imread(image_path)
# Convert the image from BGR to RGB format image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Draw the bounding box and label for each detected object for detection in detected: box = detection['box'] label = detection['label'] score = detection['score']
import torch import torchvision.transforms as transforms from PIL import Image from datasets import load_dataset from transformers import CLIPProcessor, CLIPModel
defget_text_features(text): with torch.no_grad(): inputs = processor(text=[text], return_tensors="pt", padding=True) inputs.to(device) features = model.get_text_features(**inputs) return features.cpu().numpy()
defsearch(query_text, top_k=5): # Get the text feature vector for the input query text_features = get_text_features(query_text)
# Perform a search using the FAISS index distances, indices = index.search(text_features.astype("float32"), top_k)
# Get the corresponding images and distances results = [ {"image": training_split[i]["image"], "distance": distances[0][j]} for j, i inenumerate(indices[0]) ]
return results
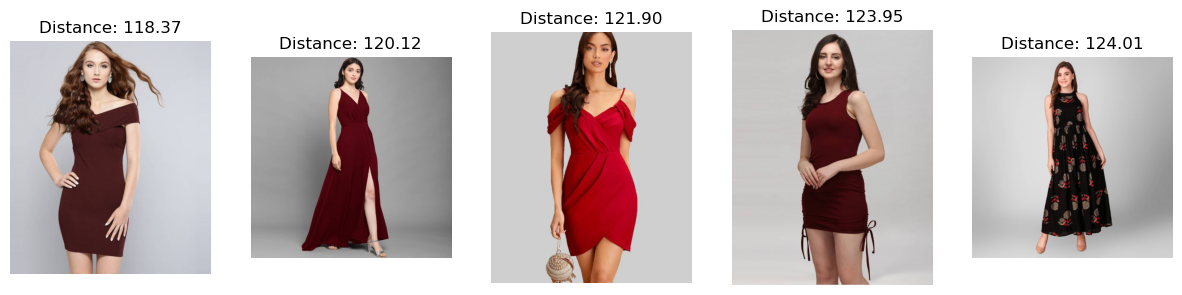
query_text = "A red dress" results = search(query_text)
for idx, result inenumerate(results): axes[idx].imshow(result["image"]) axes[idx].set_title(f"Distance: {result['distance']:.2f}") axes[idx].axis('off')
defget_image_features(image_path): # Load the image from the file image = Image.open(image_path).convert("RGB")
with torch.no_grad(): inputs = processor(images=[image], return_tensors="pt", padding=True) inputs.to(device) features = model.get_image_features(**inputs) return features.cpu().numpy()
defsearch(image_path, top_k=5): # Get the image feature vector for the input image image_features = get_image_features(image_path)
# Perform a search using the FAISS index distances, indices = index.search(image_features.astype("float32"), top_k)
# Get the corresponding images and distances results = [ {"image": training_split[i.item()]["image"], "distance": distances[0][j]} for j, i inenumerate(indices[0]) ]