
15.大语言模型如何模型微调与流式生成
15.大语言模型如何模型微调与流式生成
大部分内容来自于极客时间徐文浩-AI大模型之美
在之前介绍llama-index和LangChain的几讲里面,我们学习了如何将大语言模型和你自己的知识库组合到一起来解决问题。这个方法中,我们不需要对我们使用的模型做任何调整,而是通过将我们的数据用Embedding向量索引起来,然后在使用的时候查询索引来解决问题。
不过,其实我们也完全可以利用我们自己的数据,创建一个新的模型来回答问题。这个方法,就是OpenAI提供的模型微调(Fine-tune)功能。这也是我们要探讨的大语言模型的最后一个主题。
如何进行模型微调?
模型微调,是因为无论是ChatGPT还是GPT-4都不是全知全能的AI。在很多垂直的领域,它的回答还是常常会出错。其中很大一部分原因,是它也缺少特定领域的训练数据。而如果我们有比较丰富的垂直领域的数据,那么就可以利用这些数据来“微调”一个特别擅长这个垂直领域的模型。在这个模型“微调”完成之后,我们就可以直接向模型提问了。而不用再像之前使用llama-index或者LangChain那样,先通过Embedding来查询相关资料,然后把查找到的资料也一并提交给OpenAI来获得所需要的答案。
OpenAI模型微调的过程,并不复杂。你只需要把数据提供给OpenAI就好了,对应的整个微调的过程是在云端的“黑盒子”里进行的。需要提供的数据格式是一个文本文件,每一行都是一个Prompt,以及对应这个Prompt的Completion接口会生成的内容。
就像下面的示例:
1 | |
模型微调的过程,就是根据输入的内容,在原来的基础模型上训练。这个基础模型 Ada、Babbage、Curie和Davinci 其中的一个。每一个示例,都会导致基础模型原有参数发生变化。整个微调过程结束之后,变化后的参数就会被固定下来,变成一个只有你可以使用的新模型。
如果你提供了很多医疗行业的文本内容,那么微调出来的新模型就会拥有更多医疗领域的知识,以及对话的风格。而如果你给的是笑话大全,那么微调出来的模型就更擅长讲笑话。而且要注意,微调之后的模型,不仅有你用来微调的数据的相关知识,原先基础模型里面的绝大部分知识和能力它也还都保留着。
来一个擅长写“历史英雄人物和奥特曼一起打怪兽”的AI
那今天我们来微调一个什么样的模型呢?我周围有不少朋友家里都有孩子,都特别迷恋奥特曼打怪兽的故事。他们就向我提过一个需求,说能不能利用ChatGPT来做一个专门讲奥特曼打怪兽故事的应用。可以是可以,不过,为了让这个故事既能精彩一点,又有点教育意义,我们就再找一些历史上的英雄人物,赋予他们一些超能力,来和奥特曼一起打怪兽。而对应的故事数据,我们也用ChatGPT的模型来帮我们生成。
1 | |
这部分代码非常简单,我们定义了一系列朝代、超能力和故事的类型。然后通过三重循环,让AI根据这三者的组合来生成一系列故事。这些生成出来的故事,也就构成了我们用来微调模型的训练数据。因为数据量不大,我就直接用CSV把它存下来了。在这个过程中,数据是一条条生成的,比较慢,也比较消耗Token,你可以不用运行,直接拿我运行后生成的结果数据就好。
拿到了这些数据,我们就可以来微调模型了。我们之前已经通过pip安装了OpenAI的包,这里面自带了命令行工具,方便我们把对应的CSV格式的数据转换成微调模型所需要的JSONL格式的文件。
1 | |
输出结果:
1 | |
上面的代码主要做了两个动作。首先,是对数据做了一些处理,来准备微调。对于微调,我们使用的Prompt不再是一个完整的句子,而是只用了“朝代”+“超能力”+“故事类型”拼接在一起的字符串,中间用逗号隔开。然后把这个字符串和生成的故事,用Prompt和Completion作为列名存储成了一个CSV。
其次,我们通过subprocess调用了命令行里的OpenAI工具,把上面的CSV文件,转化成了一个JSONL格式的文件。从输出的日志里面可以看到,这个文件叫做 data/prepared_data_prepared.jsonl。
如果我们打开这个JSONL文件看一眼,是下面这样的。
1 | |
可以看到,转换后的数据文件,在Prompt的最后,多了一个“->”符号。而在Completion的开头,多了两个“\n\n”的换行,结尾则是多了一个“.”。这是为了方便我们后续在使用这个模型生成数据的时候,控制生成结果。未来在使用模型的时候,Prompt需要以“->\n”这个提示符结束,并且将stop设置成“.”。这样,模型就会自然套用我们微调里的模式来生成文本。
有了准备好的数据,我们只要再通过subprocess调用OpenAI的命令行工具,来提交微调的指令就可以了。
1 | |
输出结果:
1 | |
在这个微调的指令里面,我们指定了三个参数,分别是用来训练的数据文件、一个基础模型,以及生成模型的后缀。这里,我们选用了Curie作为基础模型,因为是讲奥特曼的故事,所以模型后缀我给它取了一个ultraman的名字。
我们的数据量不大,所以微调很快,几分钟就能完成。那接下来我们就可以使用这个模型了。我们可以通过下面的fine_tunes.list指令,找出所有我们微调的模型。
1 | |
输出结果:
1 | |
在输出的JSON里面,你可以看到我们有一个fine_tuned_model字段,里面的值叫做“curie:ft-bothub-ai:ultraman-2023-04-04-03-03-26”,这个就是刚刚让OpenAI给我们微调完的模型。
这个模型的使用方法,和我们使用text-davinci-003之类的模型是一样的,只要在API里面把对应的model字段换掉就好了,对应的代码我也放在了下面。
1 | |
输出结果:
1 | |
对应在调用模型的时候,我们使用的提示语就是“朝代”+“超能力”+“故事类型”,并且跟着“->\n”,而stop则是设置成了“.”。
因为这是一个微调的模型,它不仅拥有我们训练数据提供的知识,也包括基础模型里的各种信息。所以我们使用的朝代、超能力和故事类型也可以是在之前微调数据里面没有出现过的。比如,上面的例子里,我们使用的超能力叫做“发射激光”,并不是我们拿来微调的数据里面有的一种超能力。你可以试试看,使用别的朝代、故事的类型,效果会是怎么样的。
1 | |
输出结果:
1 | |
模型微调的成本考量
细心的人可能注意到了,我们这里选用的基础模型是Curie,而不是效果最好的Davinci。之所以做出这样的选择,是出于成本的考虑。
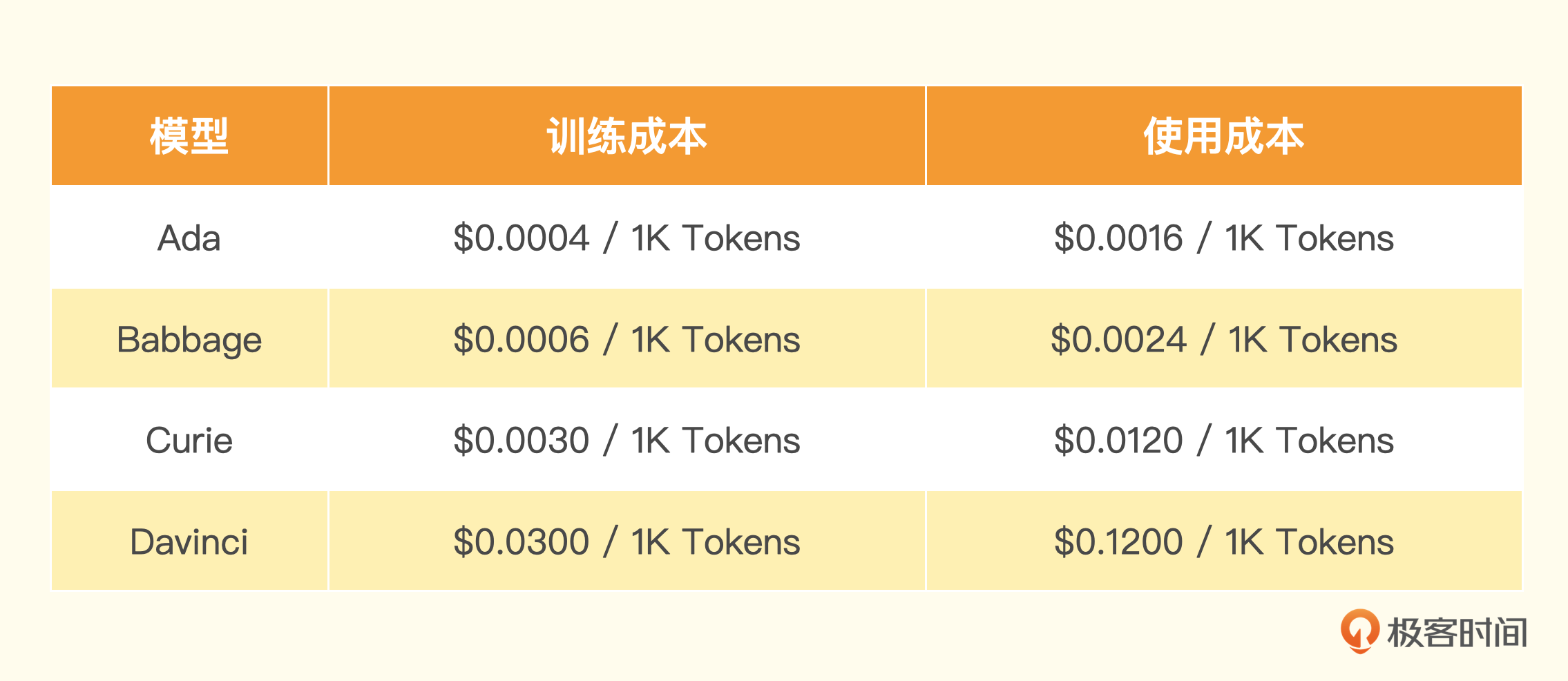
注:数据来源于 https://openai.com/pricing#language-models
使用微调模型的成本要远远高于使用OpenAI内置的模型。 以Davinci为基础微调的模型,使用的时候,每1000个Token的成本是0.12美元,是使用内置的text-davinci-003的6倍,是我们最常用的 gpt-3.5-turbo 的60倍。所以,如果只是一般的讲故事的应用,这个成本实在是太高了。就算是我们选择基于Curie微调,1000个Token的使用成本也在0.012美元,虽然比text-davinci-003要便宜,但也是gpt-3.5-turbo的6倍。
对于模型微调的效果,我们也可以通过一个OpenAI提供的命令fine_tunes.results来看。对应的,我们需要提供给它一个微调任务的id。这个id,可以在fine_tunes.list列出的fine_tunes模型的id参数里找到。
1 | |
输出结果:
1 | |
在这个命令的输出结果里,你可以在第二列elapsed_tokens看到训练消耗的Token数量。而最后一列 training_token_accuracy,则代表微调后的模型,成功预测微调的数据里下一个Token的准确率。在我们使用的这个例子里面,可以看到一开始准确率只有75%,但是随着训练数据迭代轮数的增加,准确率越来越高,达到了95%以上。
增量训练,不断优化模型
微调模型比较高昂的价格,限制了它的使用。 不过,微调模型还有一个能力,就是我们可以在已经微调了的模型上根据新数据做进一步地微调。 这个在很多垂直领域是非常有用,比如在医学、金融这样的领域,我们就可以不断收集新的数据,不断在前一个微调模型的基础之上继续微调我们的模型,让模型的效果越来越好。而这些领域往往也能承受更高一些的成本。
进一步地微调其实操作起来并不复杂,就是再准备一些数据,以之前已经微调好的模型为基础模型来操作就好了。
生成一些额外的数据:
1 | |
转换数据:
1 | |
继续微调:
1 | |
在原有的模型上微调的时候,我们要修改两个参数。
- 第一个是model参数,我们把Curie换成了我们刚才微调之后的模型 curie:ft-bothub-ai:ultraman-2023-04-04-03-03-26。
- 第二个是learning_rate_multiplier,这个参数的默认值是根据你的样本数量在0.05 到 0.2 不等。如果你继续微调的样本数要比之前微调的数据量小很多,你就可以调得大一点。
微调更新之后,模型的名称没有变,老的模型就被更新成了微调后的新模型,我们再来试一下这个新模型。
1 | |
输出结果:
1 | |
流式生成
通过模型微调,我们拥有了一个可以讲故事的AI模型。不过,故事生成的体验稍微有点差。它不像是我们在ChatGPT的Web界面里那样一个词一个词地蹦出来,就像一个真人在给你讲故事那样。不过要做到这一点也并不难,因为OpenAI的Completion接口是提供了这样返回结果的模式的,你只需要把代码小小地修改一下就好了。
1 | |
输出结果:
1 | |
我们在调用Completion接口的时候,启用了stream=True这个参数。然后对于返回结果,我们不再是直接拿到整个response然后打印出来。而是拿到一个可以通过迭代器访问的一系列events,每一个event都包含了一部分新生成的文本。你试着运行一下这段代码,就能体验到AI把一个个词吐给你,好像真的在实时讲故事一样的感觉了。
小结
这篇文章里一起学习了OpenAI大语言模型里的最后两个功能。
第一个是模型微调,模型微调给我们提供了一个非常实用的能力, 我们可以利用自己的数据,在OpenAI的基础模型上,调整模型参数生成一个新模型。这样我们就能够根据自己专有的垂直领域的数据,来生产一个专属于我们自己的模型。而且,我们可以根据新收集到的数据,不断在这个模型上继续微调迭代。不过,微调后的模型使用成本比较高,你需要自己核算一下,究竟是微调模型ROI比较高,还是使用前面的外部知识库的方式更划算一些。
在模型微调之外,我们还了解了OpenAI接口上的一个小功能,也就是 流式地数据生成。通过开启流式地文本生成,我们可以交付给用户更好的交互体验。特别是在使用比较慢的模型,比如GPT-4,或者生成的文本很长的时候,效果特别明显。用户不需要等上几十秒才能看到结果。
那到这里,大语言模型部分我们也就介绍完了。从最基本的两个API,Completion和Embedding开始,介绍了各种各样的应用场景和使用方法。可以看到,现在的大语言模型几乎是“万能”的。下可以拿来做机器学习的输入数据,上可以直接让它自己决定调用什么API,怎么解决用户的问题。相信看到这里的你,已经掌握如何使用大语言模型了,接下来就要多想想在你的实际工作里如何把它用起来了。
推荐阅读
OpenAI在自己的 官方文档 里,推荐了通过 Weight & Bias 这个公司的产品,来追踪微调后的模型的实验、模型与数据集。Weight & Bias 也在自己的 文档 里,提供了一个对WIT数据集进行模型微调的 Notebook,你有兴趣的话也可以去看一下。