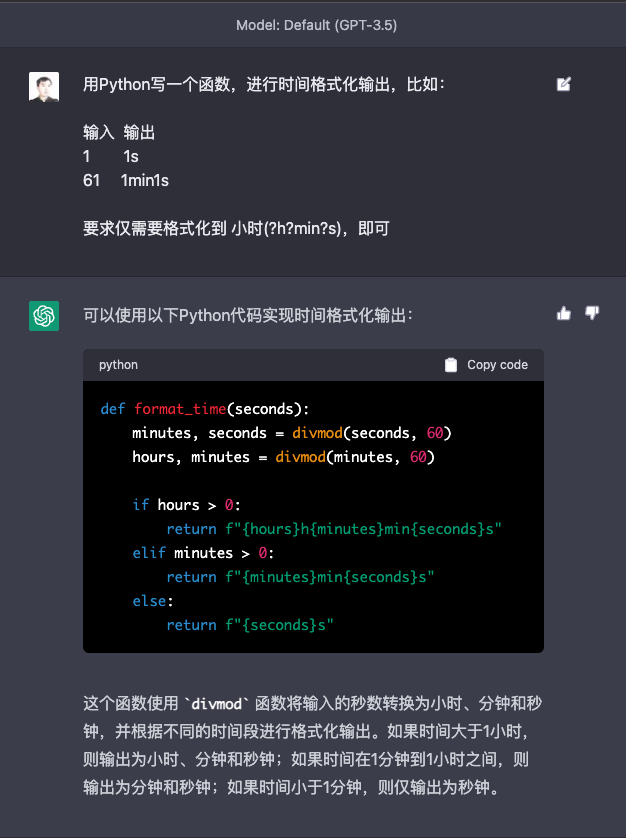
defexplain_code(function_to_test, unit_test_package="pytest"): prompt = f""""# How to write great unit tests with {unit_test_package}
In this advanced tutorial for experts, we'll use Python 3.10 and `{unit_test_package}` to write a suite of unit tests to verify the behavior of the following function. ```python {function_to_test}
Before writing any unit tests, let's review what each element of the function is doing exactly and what the author's intentions may have been. - First,""" response = gpt35(prompt) return response, prompt
we use the `divmod` built-in function to get the quotient and remainder of `seconds` divided by 60. This is assigned to the variables `minutes` and `seconds`, respectively. - Next, we do the same thing with `minutes` and 60, assigning the results to `hours` and `minutes`. - Finally, we use string interpolation to return a string formatted according to how many hours/minutes/seconds are left.
A good unit test suite should aim to: - Test the function's behavior for a wide range of possible inputs - Test edge cases that the author may not have foreseen - Take advantage of the features of `{unit_test_package}` to make the tests easy to write and maintain - Be easy to read and understand, with clean code and descriptive names - Be deterministic, so that the tests always pass or fail in the same way
`{unit_test_package}` has many convenient features that make it easy to write and maintain unit tests. We'll use them to write unit tests for the function above.
For this particular function, we'll want our unit tests to handle the following diverse scenarios (and under each scenario, we include a few examples as sub-bullets): -""" prompt = full_code_explaination + prompt_to_explain_a_plan response = gpt35(prompt) return response, prompt
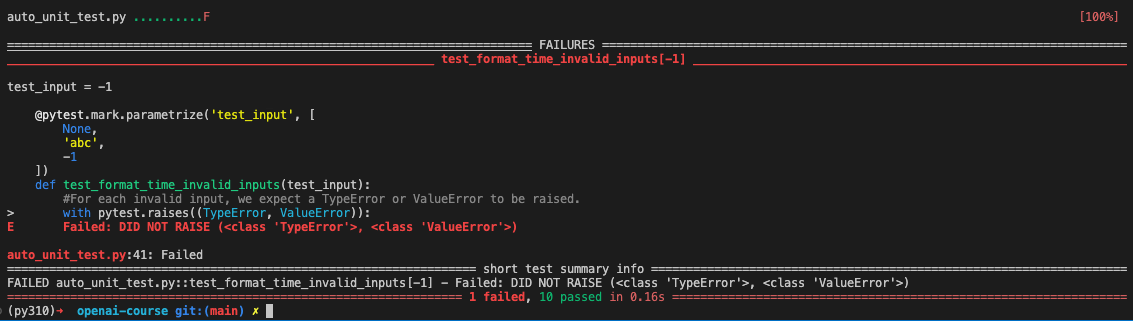
Normal behavior: - `format_time(0)` should return `"0s"` - `format_time(59)` should return `"59s"` - `format_time(60)` should return `"1min0s"` - `format_time(119)` should return `"1min59s"` - `format_time(3600)` should return `"1h0min0s"` - `format_time(3601)` should return `"1h0min1s"` - `format_time(3660)` should return `"1h1min0s"` - `format_time(7200)` should return `"2h0min0s"` - Invalid inputs: - `format_time(None)` should raise a `TypeError` - `format_time("abc")` should raise a `TypeError` - `format_time(-1)` should raise a `ValueError`
not_enough_test_plan = """The function is called with a valid number of seconds - `format_time(1)` should return `"1s"` - `format_time(59)` should return `"59s"` - `format_time(60)` should return `"1min"` """
In addition to the scenarios above, we'll also want to make sure we don't forget to test rare or unexpected edge cases (and under each edge case, we include a few examples as sub-bullets): -""" more_test_plan, prompt_to_get_test_plan = generate_a_test_plan(prompt_to_explain_code + code_explaination + not_enough_test_plan + prompt_to_elaborate_on_the_plan) print(more_test_plan)
输出结果:
1 2 3 4 5 6 7 8 9 10
The function is called with a valid number of seconds - `format_time(1)` should return `"1s"` - `format_time(59)` should return `"59s"` - `format_time(60)` should return `"1min"` - The function is called with an invalid number of seconds - `format_time(-1)` should raise a `ValueError` - `format_time("60")` should raise a `TypeError` - The function is called with a `None` value - `format_time(None)` should raise a `TypeError`
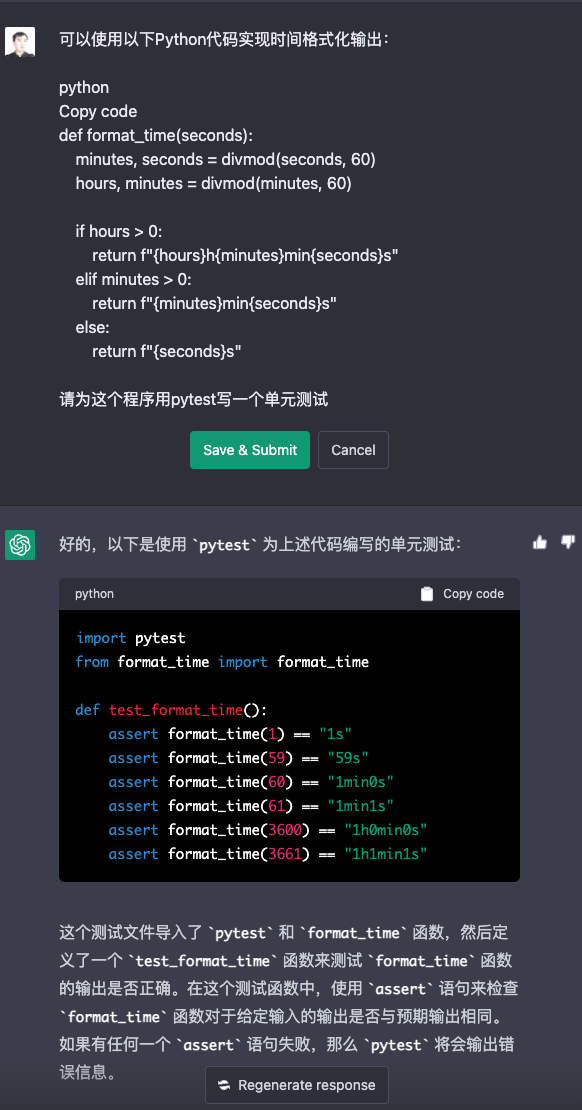
defgenerate_test_cases(function_to_test, unit_test_package="pytest"): starter_comment = "Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator" prompt_to_generate_the_unit_test = f"""
Before going into the individual tests, let's first look at the complete suite of unit tests as a cohesive whole. We've added helpful comments to explain what each line does. ```python import {unit_test_package} # used for our unit tests
. #The first element of the tuple is the name of the test case, and the second element is the value to be passed to the format_time() function. @pytest.mark.parametrize('test_input,expected', [ ('0', '0s'), ('59', '59s'), ('60', '1min0s'), ('119', '1min59s'), ('3600', '1h0min0s'), ('3601', '1h0min1s'), ('3660', '1h1min0s'), ('7200', '2h0min0s'), ]) deftest_format_time(test_input, expected): #For each test case, we call the format_time() function and compare the returned value to the expected value. assert format_time(int(test_input)) == expected
#We use the @pytest.mark.parametrize decorator again to test the invalid inputs. @pytest.mark.parametrize('test_input', [ None, 'abc', -1 ]) deftest_format_time_invalid_inputs(test_input): #For each invalid input, we expect a TypeError or ValueError to be raised. with pytest.raises((TypeError, ValueError)): format_time(test_input)
#Below, each test case is represented by a tuple passed to the @pytest.mark.parametrize decorator. #The first element of the tuple is the name of the test case, and the second element is the value to be passed to the format_time() function. @pytest.mark.parametrize('test_input,expected', [ ('0', '0s'), ('59', '59s'), ('60', '1min0s'), ('119', '1min59s'), ('3600', '1h0min0s'), ('3601', '1h0min1s'), ('3660', '1h1min0s'), ('7200', '2h0min0s'), ]) deftest_format_time(test_input, expected): #For each test case, we call the format_time() function and compare the returned value to the expected value. assert format_time(int(test_input)) == expected
#We use the @pytest.mark.parametrize decorator again to test the invalid inputs. @pytest.mark.parametrize('test_input', [ None, 'abc', -1 ]) deftest_format_time_invalid_inputs(test_input): #For each invalid input, we expect a TypeError or ValueError to be raised. with pytest.raises((TypeError, ValueError)): format_time(test_input)