08.通过Llama Index实现先搜索、后提示,成为“第二大脑”模式
大部分内容来自于极客时间徐文浩-AI大模型之美
有不少人在使用OpenAI提供的GPT系列模型的时候,都反馈效果并不好。这些反馈中有一大类问题,是回答不了一些简单的问题。比如当我们用中文问AI一些事实性的问题,AI很容易胡编乱造。而当你问它最近发生的新闻事件的时候,它就干脆告诉你它不知道21年之后的事情。
本来呢,我写到这里就可以了。不过到了3月24日,OpenAI推出了ChatGPT Plugins这个功能,可以让ChatGPT通过插件的形式链接外部的第三方应用。我自己也还在排队等waiting list,所以暂时也无法体验。不过,即使有了第三方应用,我们也不能确保自己想要知道的信息正好被其他人提供了。而且,有些信息和问题我们只想提供给自己公司的内部使用,并不想开放给所有人。这个时候,我们既希望能够利用OpenAI的大语言模型的能力,但是又需要这些能力仅仅在我们自己指定的数据上。那么这一讲,就是为了解决这个问题的。
大型语言模型的不足之处 我们先来尝试问ChatGPT一个人尽皆知的常识,“鲁迅先生去日本学习医学的老师是谁”,结果它给出的答案是鲁迅的好友,内山书店的老板内山完造,而不是大家都学习过的藤野先生。
之所以会出现这样的情况,和大模型的原理以及它使用训练的数据集是有关的。大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。而在GPT-3的模型里,虽然整体的训练语料很多,但是中文语料很少。只有不到1%的语料是中文的,所以如果问很多中文相关的知识性或者常识性问题,它的回答往往就很扯。
当然,你可以说我们有一个解决办法,就是多找一些高质量的中文语料训练一个新的模型。或者,对于我们想让AI能够回答出来的问题,找一些数据。然后利用OpenAI提供的“微调”(Fine-tune)接口,在原来的基础上训练一个新模型出来。
这样当然是可以的,就是成本有点高。对于上面那个例子来说,只是缺少一些文本数据,还好说。如果是时效性要求比较强的资讯类的信息,就很难这么做。比如,我们想让AI告诉我们前一天足球赛的比分,我们不太可能每隔几个小时就单独训练或者微调一下模型,那样干的成本太高了。
Bing的解法——先搜索,后提示 不过对这个领域比较关注的朋友可能就要问了。之前微软不是在Bing这个搜索引擎里,加上了ChatGPT的问答功能吗?效果似乎也还不错,那Bing是怎么做到的呢,是因为他们用了更加厉害的语言模型吗?
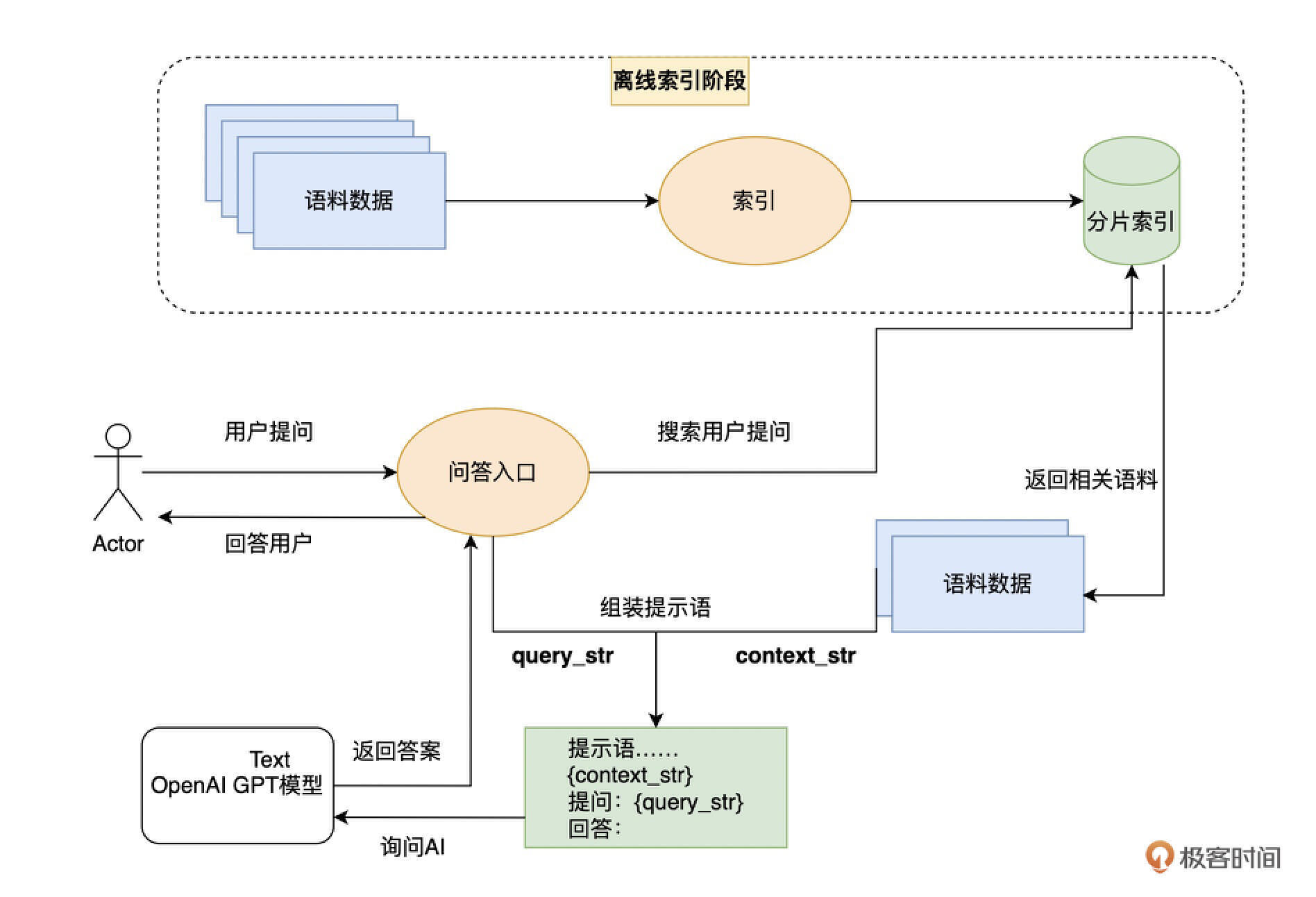
最可能的解决办法——那就是先搜索,后提示(Prompt)。
我们先通过搜索的方式,找到和询问的问题最相关的语料。这个搜索过程中,我们既可以用传统的基于关键词搜索的技术,也可以使用Embedding的相似度进行语义搜索的技术。
然后,我们将和问题语义最接近的前几条内容,作为提示语的一部分给到AI。然后请AI参考这些内容,再来回答这个问题。
我在这里,也给了你一个例子的截图。当我们把《藤野先生》里的两个段落给到AI,然后请AI根据这两个段落,回答原来那个问题,就会得到正确的答案,你也可以去看一看。
这也是利用大语言模型的一个常见模式。因为大语言模型其实内含了两种能力。
第一种,是海量的语料中,本身已经包含了的知识信息。比如,我们前面问AI鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
第二种,是根据你输入的内容,理解和推理的能力。这个能力,不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来,临时提供给模型的。如果不提供这个上下文,再问一次模型相同的问题,它还是答不上来的。
通过llama_index封装“第二大脑” 给上面这种先搜索、后提示的方式,取了一个名字,叫做AI的“第二大脑”模式。因为这个方法,需要提前把你希望AI能够回答的知识,建立一个外部的索引,这个索引就好像AI的“第二个大脑”。每次向AI提问的时候,它都会先去查询一下这个第二大脑里面的资料,找到相关资料之后,再通过自己的思维能力来回答问题。
实际上,你现在在网上看到的很多读论文、读书回答问题的应用,都是通过这个模式来实现的。那么,现在我们就来自己实现一下这个“第二大脑”模式。
不过,我们不必从0开始写代码。因为这个模式实在太过常用了,所以有人为它写了一个开源Python包,叫做llama-index。那么我们这里,可以直接利用这个软件包,用几行代码来试一试,它能不能回答上鲁迅先生写的《藤野先生》相关的问题。
llama-index还没有人做好Conda下的包,所以即使在Conda下还是要通过pip来安装。
1 2 3 pip install llama-index
我把从网上找到的《藤野先生》这篇文章变成了一个txt文件,放在了 data/mr_fujino 这个目录下。我们的代码也非常简单,一共没有几行。
1 2 3 4 5 6 7 8 9 10 import openai, osfrom llama_index import GPTVectorStoreIndex, SimpleDirectoryReader"OPENAI_API_KEY" )'./data/mr_fujino' ).load_data()'index_mr_fujino.json' )
输出结果:
1 2 3 INFO:llama_index.token_counter.token_counter:> [build_index_from_nodes] Total LLM token usage: 0 tokens6763 tokens
注:日志中会打印出来我们通过Embedding消耗了多少个Token。
首先,我们通过一个叫做SimpleDirectoryReader的数据加载器,将整个./data/mr_fujino 的目录给加载进来。这里面的每一个文件,都会被当成是一篇文档。
然后,我们将所有的文档交给了 GPTSimpleVectorIndex 构建索引。顾名思义,它会把文档分段转换成一个个向量,然后存储成一个索引。
最后,我们会把对应的索引存下来,存储的结果就是一个json文件。后面,我们就可以用这个索引来进行相应的问答。
1 2 3 4 index = GPTVectorStoreIndex.load_from_disk('index_mr_fujino.json' )"鲁迅先生在日本学习医学的老师是谁?" )print (response)
要进行问答也没有几行代码,我们通过 GPTSimpleVectorIndex 的 load_from_disk 函数,可以把刚才生成的索引加载到内存里面来。然后对着Index索引调用Query函数,就能够获得问题的答案。可以看到,通过外部的索引,我们可以正确地获得问题的答案。
1 2 3 4 5 INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 2984 tokens34 tokens
这么一看,似乎问题特别简单,三行代码就搞定了。别着急,我们再看看别的问题它是不是也能答上来?这次我们来试着问问鲁迅先生是在哪里学习医学的。
1 2 3 response = index.query("鲁迅先生去哪里学的医学?" )print (response)
输出结果:
1 2 3 4 5 6 7 8 9 > Got node text: 藤野先生2969 tokens26 tokens
它仍然正确回答了问题。那么,我们搜索到的内容,在这个过程里面是如何提交给OpenAI的呢?我们就来看看下面的这段代码就知道了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from llama_index import QuestionAnswerPrompt"鲁迅先生去哪里学的医学?" "Context information is below. \n" "---------------------\n" "{context_str}" "\n---------------------\n" "Given the context information and not prior knowledge, " "answer the question: {query_str}\n" print (response)
这段代码里,我们定义了一个QA_PROMPT的对象,并且为它设计了一个模版。
这个模版的开头,我们告诉AI,我们为AI提供了一些上下文信息(Context information)。
模版里面支持两个变量,一个叫做 context_str,另一个叫做query_str。context_str 的地方,在实际调用的时候,会被通过Embedding相似度找出来的内容填入。而 query_str 则是会被我们实际提的问题替换掉。
实际提问的时候,我们告诉AI,只考虑上下文信息,而不要根据自己已经有的先验知识(prior knowledge)来回答问题。
我们就是这样,把搜索找到的相关内容以及问题,组合到一起变成一段提示语,让AI能够按照我们的要求来回答问题。那我们再问一次AI,看看答案是不是没有变。
输出结果:
这一次AI还是正确地回答出了鲁迅先生是去仙台的医学专门学校学习的。我们再试一试,问一些不相干的问题,会得到什么答案,比如我们问问红楼梦里林黛玉和贾宝玉的关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 QA_PROMPT_TMPL = ("下面的“我”指的是鲁迅先生 \n" "---------------------\n" "{context_str}" "\n---------------------\n" "根据这些信息,请回答问题: {query_str}\n" "如果您不知道的话,请回答不知道\n" "请问林黛玉和贾宝玉是什么关系?" , text_qa_template=QA_PROMPT)print (response)
输出结果:
可以看到,AI的确按照我们的指令回答不知道,而不是胡答一气。
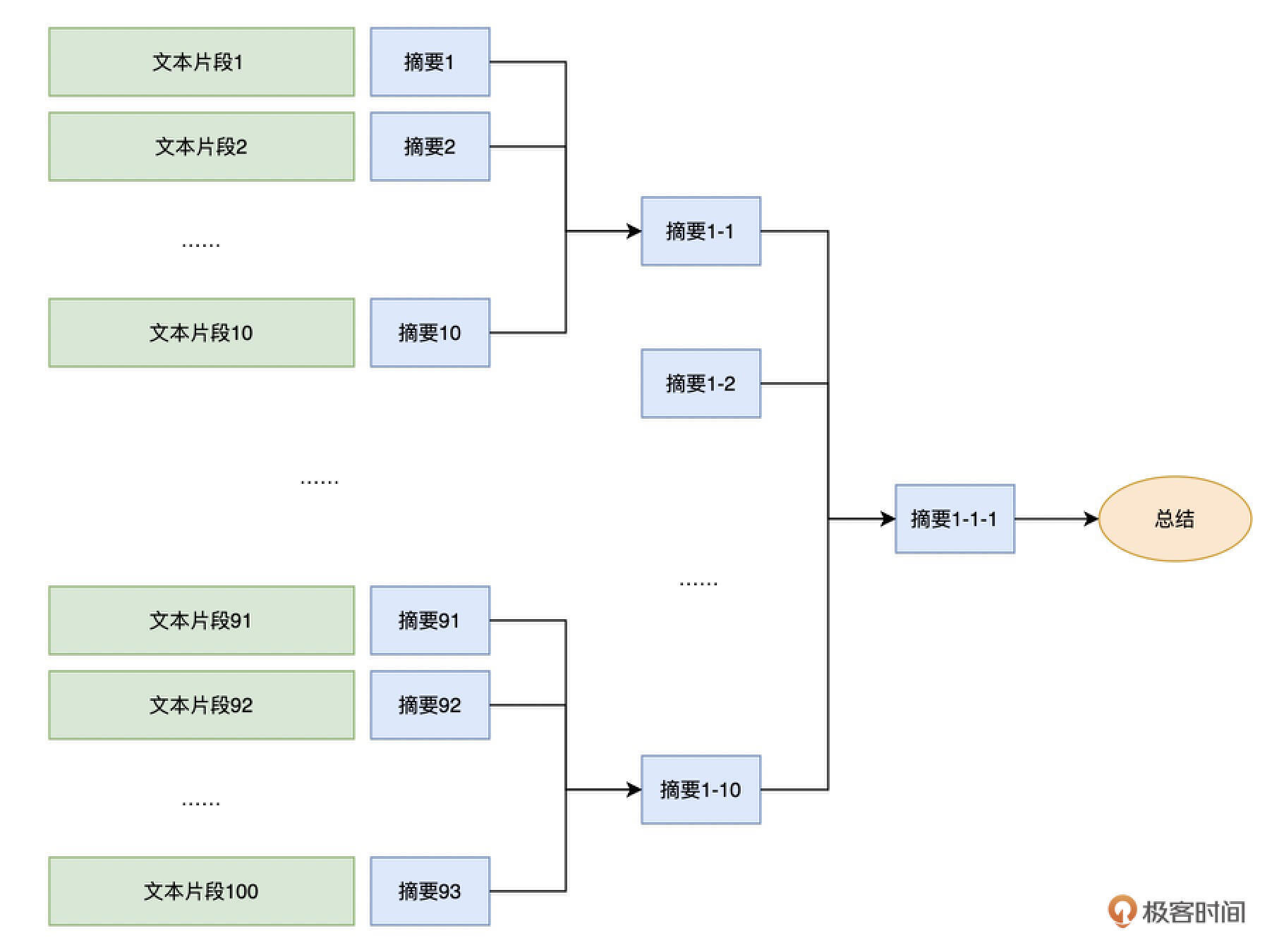
通过llama_index对于文章进行小结 还有一个常见的使用llama-index这样“第二大脑”的Python库的应用场景,就是生成文章的摘要。在前面教你如何进行文本聚类的时候,我们已经看到了可以通过合适的提示语(Prompt)做到这一点。不过,如果要总结一篇论文、甚至是一本书,每次最多只能支持4096个Token的API就不太够用了。
要解决这个问题也并不困难,我们只要进行分段小结,再对总结出来的内容再做一次小结就可以了。我们可以把一篇文章,乃至一本书,构建成一个树状的索引。每一个树里面的节点,就是它的子树下内容的摘要。最后,在整棵树的根节点,得到的就是整篇文章或者整本书的总结了。
事实上,llama-index本身就内置了这样的功能。下面我们就来看看要实现这个功能,我们的代码应该怎么写。
首先,我们先来安装一下 spaCy 这个Python库,并且下载一下对应的中文分词分句需要的模型。
1 2 3 pip install spacy
接下来的代码很简单,我们选用了GPTListIndex这个llama-index里最简单的索引结构。不过我们针对自身需求做了两点优化。
首先,在索引里面,我们指定了一个 LLMPredictor,让我们向OpenAI发起请求的时候,都使用ChatGPT的模型。因为这个模型比较快,也比较便宜。llama-index默认使用的模型是text-davinci-003,价格比gpt-3.5-turbo要贵上十倍。在我们前面只是简单进行几轮对话的时候,这个价格差异还不明显。而如果你要把几十本书都灌进去,那成本上就会差上不少了。我们在这里,设置了模型输出的内容都在1024个Token以内,这样可以确保我们的小结不会太长,不会把一大段不相关的内容都合并到一起去。
其次,我们定义了使用 SpacyTextSplitter来进行中文文本的分割。llama-index默认的设置对于中文的支持和效果都不太好。不过好在它可以让你自定义使用的文本分割方式。我们选用的文章是中文的,里面的标点符号也都是中文的,所以我们就用了中文的语言模型。我们也限制了分割出来的文本段,最长不要超过2048个Token,这些参数都可以根据你实际用来处理的文章内容和属性自己设置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from langchain.chat_models import ChatOpenAIfrom langchain.text_splitter import SpacyTextSplitterfrom llama_index import GPTListIndex, LLMPredictor, ServiceContextfrom llama_index.node_parser import SimpleNodeParser0 , model_name="gpt-3.5-turbo" , max_tokens=1024 ))"zh_core_web_sm" , chunk_size = 2048 )'./data/mr_fujino' ).load_data()
输出结果:
1 2 3 4 WARNING:llama_index.llm_predictor.base:Unknown max input size for gpt-3.5 -turbo, using defaults.0 tokens0 tokens
GPTListIndex在构建索引的时候,并不会创建Embedding,所以索引创建的时候很快,也不消耗Token数量。它只是根据你设置的索引结构和分割方式,建立了一个List的索引。
接着,我们就可以让AI帮我们去小结这篇文章了。同样的,提示语本身很重要,所以我们还是强调了文章内容是鲁迅先生以“我”这个第一人称写的。因为我们想要的是按照树状结构进行文章的小结,所以我们设定了一个参数,叫做 response_mode = “tree_summarize”。这个参数,就会按照上面我们所说的树状结构把整个文章总结出来。
实际上,它就是将每一段文本分片,都通过query内的提示语小结。再对多个小结里的内容,再次通过query里的提示语继续小结。
1 2 3 response = list_index.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:" , response_mode="tree_summarize" )print (response)
输出结果:
1 2 3 4 5 INFO:llama_index.indices.common_tree.base:> Building index from nodes: 2 chunks9787 tokens0 tokens
可以看到,我们只用了几行代码就完成了整个文章的小结,返回的结果整体上来说也还算不错。
引入多模态,让llamd-index能够识别小票 llama_index不光能索引文本,很多书里面还有图片、插画这样的信息。llama_index一样可以索引起来,供你查询,这也就是所谓的多模态能力。当然,这个能力其实是通过一些多模态的模型,把文本和图片能够联系到一起做到的。在整个课程的第三部分,我们也会专门来看看这些图像的多模态模型是怎么样的。
这里我们就来看一个llama_index 官方样例库 里面给到的例子,也就是把吃饭的小票都拍下来。然后询问哪天吃了什么,花了多少钱。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from llama_index import SimpleDirectoryReader, GPTVectorStoreIndexfrom llama_index.readers.file.base import DEFAULT_FILE_EXTRACTOR, ImageParserfrom llama_index.response.notebook_utils import display_response, display_imagefrom llama_index.indices.query.query_transform.base import ImageOutputQueryTransformTrue , parse_text=True )".jpg" : image_parser,".png" : image_parser,".jpeg" : image_parser,lambda filename: {'file_name' : filename}'./data/receipts' ,
要能够索引图片,我们引入了ImageParser这个类,这个类背后,其实是一个基于OCR扫描的模型 Donut 。它通过一个视觉的Encoder和一个文本的Decoder,这样任何一个图片能够变成一个一段文本,然后我们再通过OpenAI的Embedding把这段文本变成了一个向量。
我们仍然只需要使用简单的SimpleDirectoryReader,我们通过指定FileExtractor,会把对应的图片通过ImageParser解析成为文本,并最终成为向量来用于检索。
然后,我们仍然只需要向我们的索引用自然语言提问,就能找到对应的图片了。在提问的时候,我们专门制定了一个ImageOutputQueryTransform,主要是为了在输出结果的时候,能够在图片外加上 <img> 的标签方便在Notebook里面显示。
1 2 3 4 5 6 7 8 9 receipts_index = GPTVectorStoreIndex.from_documents(receipt_documents)'When was the last time I went to McDonald\'s and how much did I spend. \ Also show me the receipt from my visit.' ,400 )
输出结果:
1 2 3 4 5 INFO:llama_index.token_counter.token_counter:> [query] Total LLM token usage: 1004 tokens30 tokens's was on 03/10/2018 at 07:39:12 PM and you spent $26.15. Here is the receipt from your visit:
可以看到,答案中不仅显示出了对应的图片,也给出了正确的答案,这也要归功于OpenAI对于任意文本强大的处理能力。
我们可以单独解析一下图片,看看对应的文本内容是什么。
1 2 3 output_image = image_parser.parse_file('./data/receipts/1100-receipt.jpg' )print (output_image.text)
输出结果:
1 2 <s_menu><s_nm> Story</s_nm><s_num> 16725 Stony Platin Rd</s_nm><s_num> Store#:</s_nm><s_num> 3659</s_num><s_price> 700-418-8362</s_price><sep/><s_nm> Welcome to all day breakfast dormist O Md Donald's</s_nm><s_num> 192</s_num><s_price> 192</s_price><sep/><s_nm> QTY ITEM</s_nm><s_num> OTAL</s_num><s_unitprice> 03/10/2018</s_unitprice><s_cnt> 1</s_cnt><s_price> 07:39:12 PM</s_price><sep/><s_nm> Delivery</s_nm><s_cnt> 1</s_cnt><s_price> 0.00</s_price><sep/><s_nm> 10 McNuggets EVM</s_nm><s_cnt> 1</s_cnt><s_price> 10.29</s_price><sep/><s_nm> Barbeque Sauce</s_nm><s_cnt> 1</s_cnt><s_price> 1</s_price><sep/><s_nm> Barbeque Sauce</s_nm><s_num> 1</s_cnt><s_price> 0.40</s_price><sep/><s_nm> L Coke</s_nm><s_cnt> 1</s_cnt><s_price> 0.40</s_price><sep/><s_nm> M French Fries</s_nm><s_cnt> 1</s_cnt><s_price> 3.99</s_price><sep/><s_nm> HM GrChS S-Fry Yog</s_nm><s_cnt> 1</s_cnt><sep/><s_nm> Smoonya</s_nm><s_cnt> 1</s_cnt><sep/><s_nm> HM Apple Juice</s_nm><s_cnt> 1</s_cnt><s_price> 2.89</s_price><sep/><s_nm> Cookies</s_nm><s_cnt> 6</s_cnt><s_price> 2.89</s_price><sep/><s_nm> Choc Chip Cookie</s_nm><s_cnt> 6</s_cnt><s_price> 1.19</s_price><sep/><s_nm> Baked Apple Pie</s_nm><s_cnt> 1</s_cnt><s_price> 3.29</s_price><sep/><s_nm> French Fries</s_nm><s_cnt> 1</s_cnt><s_price> 2.99</s_price><sep/><s_nm> Iced Tea</s_nm><s_cnt> 1</s_cnt><s_price> 2.99</s_price></s_menu><s_sub_total><s_subtotal_price> 25.04</s_subtotal_price><s_tax_price> 1.11</s_tax_price></s_sub_total><s_total><s_total_price> 26.15</s_total_price><s_changeprice> 0.00</s_changeprice><s_creditcardprice> 26.15</s_creditcardprice></s_total>
可以看到,对应的就是OCR后的文本结果,里面的确有对应我们去的店铺的名字和时间,以及消费的金额。
围绕OpenAI以及整个大语言模型的生态还在快速发展中,所以llama-index这个库也在快速迭代。在使用的过程中,也遇到各种各样的小Bug。对于中文的支持也有各种各样的小缺陷。不过,作为开源项目,它已经有一个很不错的生态了,特别是提供了大量的DataConnector,既包括PDF、ePub这样的电子书格式,也包括YouTube、Notion、MongoDB这样外部的数据源、API接入的数据,或者是本地数据库的数据。你可以在 llamahub.ai 看到社区开发出来的读取各种不同数据源格式的DataConnector。
小结 好了,相信经过这一讲,你已经能够上手使用llama-index这个Python包了。通过它,你可以快速将外部的资料库变成索引,并且通过它提供的query接口快速向文档提问,也能够通过将文本分片,并通过树状的方式管理索引并进行小结。
llama-index还有很多其他功能,这个Python库仍然在发展过程中,不过已经非常值得拿来使用,加速你开发大语言模型类的相关应用了。相关的文档,可以在 官网 看到。对应的代码也是开源的,遇到问题也可以直接去 源代码 里一探究竟。
llama-index其实给出了一种使用大语言模型的设计模式,作者称之为“第二大脑”模式。通过先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过AI的语义理解能力让AI基于搜索到的结果来回答问题。
其中,前两步的索引和搜索,我们可以使用OpenAI的Embedding接口,也可以使用其它的大语言模型的Embedding,或者传统的文本搜索技术。只有最后一步的问答,往往才必须使用OpenAI的接口。我们不仅可以索引文本信息,也可以通过其他的模型来把图片变成文本进行索引,实现所谓的多模态功能。
希望通过今天的这几个例子,你也能开始建立起自己的“第二大脑”资料库,能够将自己的数据集交给AI进行索引,获得一个专属于你自己的AI。
推荐阅读 llama-index的功能非常强大,并且源代码里也专门提供了示例部分。你可以去看一下它的官方文档以及示例,了解它可以用来干什么。
官方文档: https://gpt-index.readthedocs.io/en/latest/
源码以及示例: https://github.com/jerryjliu/llama_index