
01.大模型学习的必备工具和准备
01.大模型学习的必备工具和准备
大部分内容来自于极客时间徐文浩-AI大模型之美
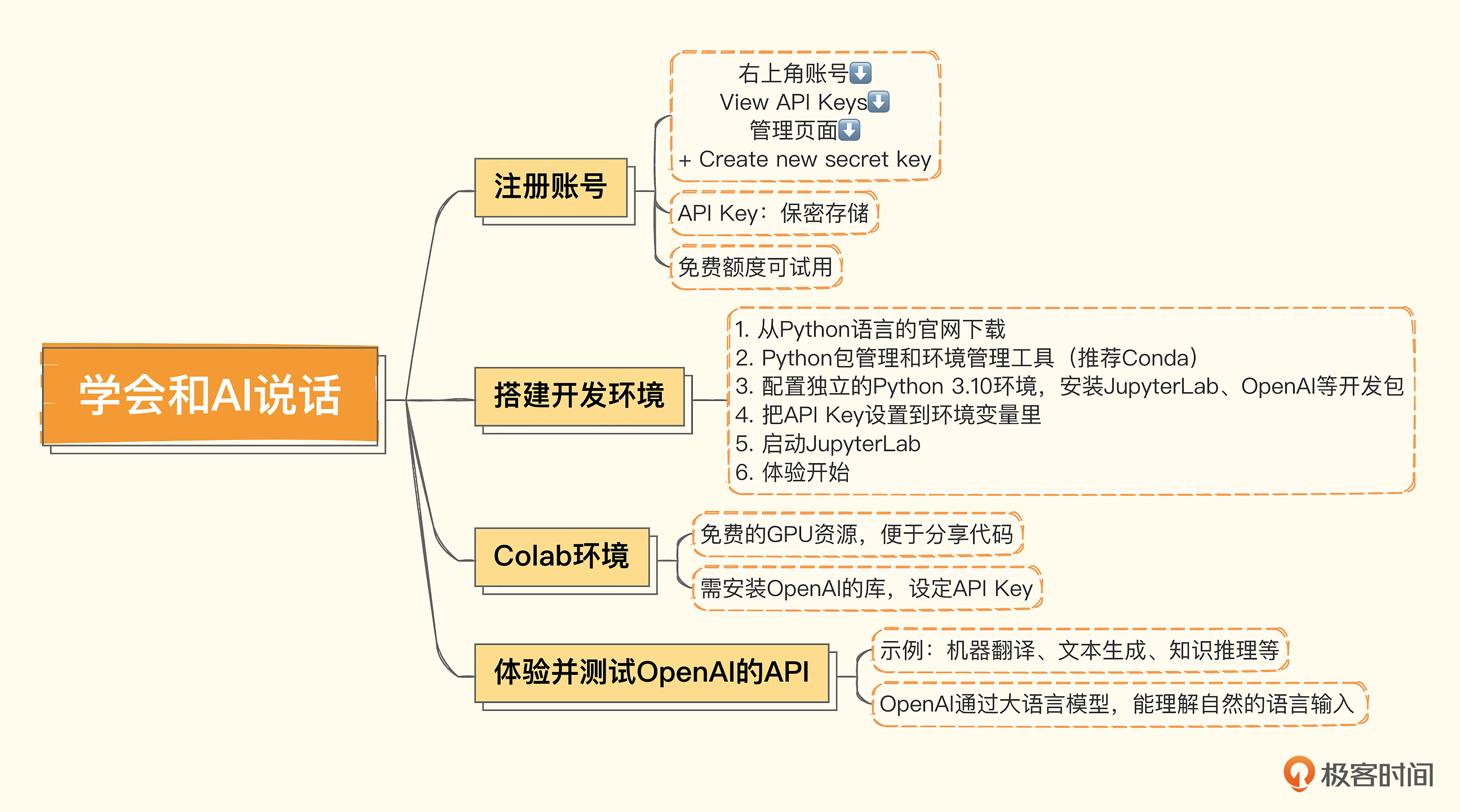
一、创建OpenAI的账号和获取API Key
这里推荐直接查看下述链接进行OpenAI账号注册:最新 OpenAI ChatGPT 3分钟注册指南(完全免费)
注册后就可以免费使用GPT3.5,当然如果要使用GPT4.0版本的话可以每个月支付20美元或者使用免费的代理网址,这里推荐以下链接进行查询使用:https://ai-bot.cn/how-to-use-gpt-4-for-free/
我这里用的比较多的是**Perplexity AI**,Perplexity AI 是一个智能搜索引擎,结合了 GPT-4 技术和即时网络搜索的人工智能工具。它使用类似于 ChatGPT 的大型语言模型,能够自动完成即时、准确和广泛的网络信息搜索,帮助用户自动筛选和整合搜索内容。与传统搜索引擎不同,Perplexity AI 会对搜索结果进行摘要,提供直接答案并提供引用,以便验证信息的准确性。它的目标是解锁知识的力量,实现信息的发现和共享。
二、本地搭建Jupyter Labs开发环境
有了API Key之后,我们还需要搭建一个开发环境。接下来主要通过 Python 来讲解和演示如何使用好AI。
一般来说,还需要一个Python的包管理和环境管理工具,这里使用 Conda。
最后,还需要通过包管理工具,配置一个独立的Python 3.10的环境,并安装好JupyterLab、OpenAI以及后面要用到的一系列开发包。我把对应的Conda命令也列在了下面,供你参考。
1 | |
后续,随着我们课程的进展,你可能还需要通过Conda或者pip来安装更多Python包。
安装完JupyterLab之后,你只需要把刚才我们获取到的API Key设置到环境变量里,然后启动JupyterLab。你可以从浏览器里,通过Jupyter Notebook交互式地运行这个课程后面的代码,体验OpenAI的大语言模型神奇的效果。
1 | |
你可以选择新建Python 3的Notebook,来体验交互式地运行Python代码调用OpenAI的API。
三、通过Colab使用JupyterLab
如果你不是一个程序员,或者你懒得在本地搭建一个开发环境。还有一个选择,就是使用Google提供的叫做 Colab 的线上Python Notebook环境。
即使你已经有了本地的开发环境,也建议注册一个账号。因为Colab可以让你免费使用一些GPU的资源,在你需要使用GPU尝试训练一些深度学习模型,而又没有一张比较好的显卡的时候,就可以直接使用它。另一方面,Colab便于你在网络上把自己撰写的Python代码分享给其他人。
Colab已经是一个Python Notebook的环境了。所以我们不需要再去安装Python和JupyterLab了。不过我们还是需要安装OpenAI的库,以及设定我们的API Key。你只需要在Notebook开始的时候,执行下面这样一小段代码就可以做到这一点。
1 | |
不过需要注意,如果你需要将Notebook分享出去,记得把其中OpenAI的API key删除掉,免得别人的调用,花费都算在了你头上。
四、体验并测试OpenAI的API
好了,现在环境已经搭建好了。无论你是使用本地的JupyterLab环境,还是使用Google免费提供的Colab环境,在这里放了一段代码,你可以把它贴到你的Notebook里面,直接运行一下。
1 | |
来看看返回结果。
1 | |
这个商品名称不是我构造的,而是直接找了1688里一个真实存在的商品。
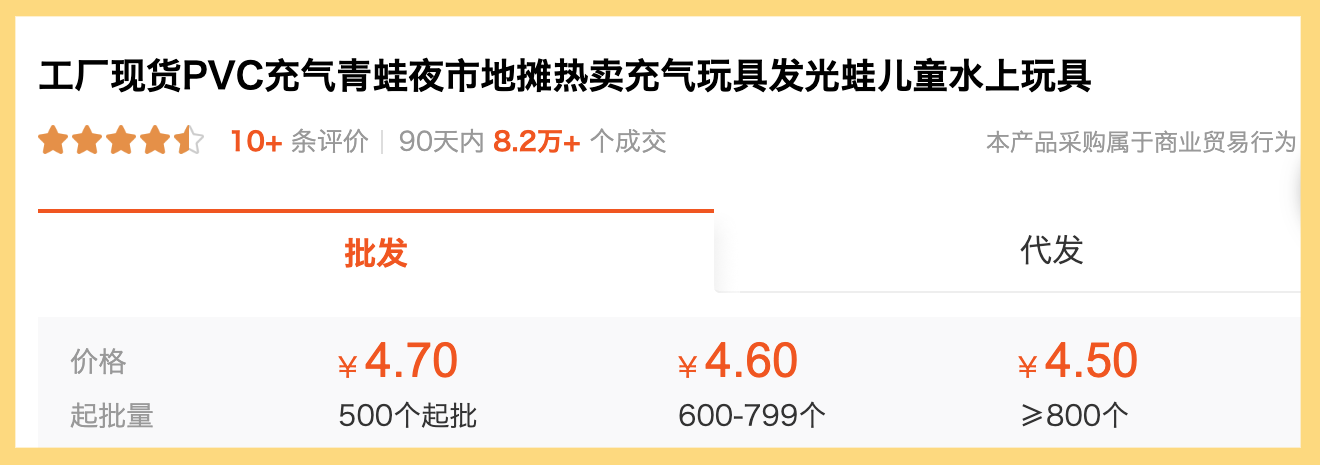
这段代码里面,我们调用了OpenAI的Completion接口,然后向它提了一个需求,也就是为一个我在1688上找到的中文商品名称做三件事情。
- 为这个商品写一个适合在亚马逊上使用的英文标题。
- 给这个商品写5个卖点。
- 估计一下,这个商品在美国卖多少钱比较合适。
同时,我们告诉OpenAI,我们希望返回的结果是JSON格式的,并且上面的三个事情用title、selling_points 和 price_range 三个字段返回。
神奇的是,OpenAI真的理解了我们的需求,返回了一个符合我们要求的JSON字符串给我们。在这个过程中,它完成了好几件不同的事情。
第一个是 翻译,我们给的商品名称是中文的,返回的内容是英文的。
第二个是 理解你的语义去生成文本,我们这里希望它写一个在亚马逊电商平台上适合人读的标题,所以在返回的英文结果里面,AI没有保留原文里有的“工厂现货”的含义,因为那个明显不适合在亚马逊这样的平台上作为标题。下面5条描述也没有包含“工厂现货”这样的信息。而且,其中的第三条卖点 “Inflatable design for easy storage and transport”,也就是作为一个充气的产品易于存放和运输,这一点其实是从“充气”这个信息AI推理出来的,原来的中文标题里并没有这样的信息。
第三个是 利用AI自己有的知识给商品定价,这里它为这个商品定的价格是在10~20美元之间。而我用 “Glow-in-the-Dark frog” 在亚马逊里搜索,搜索结果的第一行里,就有一个16美元发光的青蛙。
最后是 根据我们的要求把我们想要的结果,通过一个 JSON 结构化地返回给我们。而且,尽管我们没有提出要求,但是AI还是很贴心地把5个卖点放在了一个数组里,方便你后续只选取其中的几个来用。返回的结果是JSON,这样方便了我们进一步利用返回结果。比如,我们就可以把这个结果解析之后存储到数据库里,然后展现给商品运营人员。
好了,如果看到这个结果你有些激动的话,请你先平复一下,我们马上来看一个新例子。
1 | |
输出结果:
1 | |
我们给了它一个英文的体育新闻的标题,然后让AI把其中的人名提取出来。可以看到,返回的结果也准确地把新闻里面唯一出现的人名——曼联队的主教练滕哈格的名字提取了出来。
和之前的例子不同,这个例子里,我们希望AI处理的内容是英文,给出的指令则是中文。不过AI都处理得很好,而且我们的输入完全是自然的中英文混合在一起,并没有使用特定的标识符或者分隔符。
注:第一个例子,我们希望AI处理的内容是中文,给出的指令是英文。
我们这里的两个例子,其实对应着很多不同的问题,其中就包括 机器翻译、文本生成、知识推理、命名实体识别 等等。在传统的机器学习领域,对于其中任何一个问题,都可能需要一个独立的机器学习模型。就算把这些模型都免费提供给你,把这些独立的机器学习模型组合到一起实现上面的效果,还需要海量的工程研发工作。没有一个数十人的团队,工作量根本看不到头。
然而,OpenAI通过一个包含1750亿参数的大语言模型,就能理解自然的语言输入,直接完成各种不同的问题。而这个让人惊艳的表现,也是让很多人惊呼“通用人工智能(AGI)要来了”的原因。
五、小结
OpenAI提供的GPT-3.5系列的大语言模型,可以让你使用一个模型来解决所有的自然语言处理问题。原先我们需要一个个地单独训练模型,或者至少需要微调模型的场景,在大语言模型之下都消失了。这大大降低了我们利用AI解决问题的门槛,无论之前我们通过各种开源工具将机器学习变得多么便捷,想要做好自然语言处理,还是需要一些自然语言处理的专家。而且,往往我们还需要组合好多个模型,进行大量的工程开发工作。
而在大语言模型时代,我们只需要有会向AI提问的应用开发工程师,就能开发AI应用了。这也是我设计这门课程的目的,希望能让你体会到当前开发AI工具的便利性。
六、推荐阅读
6.1如果你想知道GPT系列大模型到底是怎么回事儿,推荐去看一下李沐老师讲解GPT系列论文的视频 GPT、GPT-2、GPT-3 论文精读,这个视频深入浅出,能够让你理解为什么现在GPT那么火热。