
Linux中线程和进程到底有啥区别?
Linux中线程和进程到底有啥区别?
主要内容转载自张彦飞的Linux中线程和进程到底有啥区别?
一、概述
1.1 基本概念:
进程是对运行时程序的封装,是系统进行资源分配的基本单位,实现了操作系统的并发;
线程是进程的子任务,是CPU调度和执行的基本单位,用于保证程序的实时性,实现进程内部的并发;线程是操作系统可识别的最小执行和调度单位。每个线程都独自占用一个虚拟处理器:独自的寄存器组,指令计数器和处理器状态。每个线程完成不同的任务,但是共享同一地址空间(也就是同样的动态内存,映射文件,目标代码等等),打开的文件队列和其他内核资源。
1.2 区别:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
- 进程是资源分配的最小单位,线程是CPU调度的最小单位;
- 系统开销: 由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/o设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,进程切换的开销也远大于线程切换的开销。
- 通信:由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。在有的系统中,线程的切换、同步和通信都无须操作系统内核的干预
- 进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
- 进程间不会相互影响 ;线程一个线程挂掉将导致整个进程挂掉
- 进程适应于多核、多机分布;线程适用于多核
二、线程的创建方法
在 Redis 6.0 以上的版本里,也开始支持使用多线程来提供核心服务,我们就以它为例。
在 Redis 主线程启动以后,会调用 initThreadedIO 来创建多个 io 线程。
redis 源码地址:https://github.com/redis/redis
1 | |
创建线程具体调用的是 pthread_create 函数,pthread_create 是在 glibc 库中实现的。在 glibc 库中,pthread_create 函数的实现调用路径是 __pthread_create_2_1 -> create_thread。 其中 create_thread 这个函数比较重要,它设置了创建线程时使用的各种 flag 标记。
1 | |
在上面的代码中,传入参数中的各个 flag 标记是非常关键的。这里我们先知道一下传入了 CLONE_VM、CLONE_FS、CLONE_FILES 等标记就行了,后面我们会讲内核中针对这些参数做的特殊处理。
接下来的 do_clone 最终会调用一段汇编程序,在汇编里进入 clone 系统调用,之后会进入内核中进行处理。
1 | |
三、内核中对线程的表示
在开始介绍线程的创建过程之前,先给大家看看内核中表示线程的数据结构。
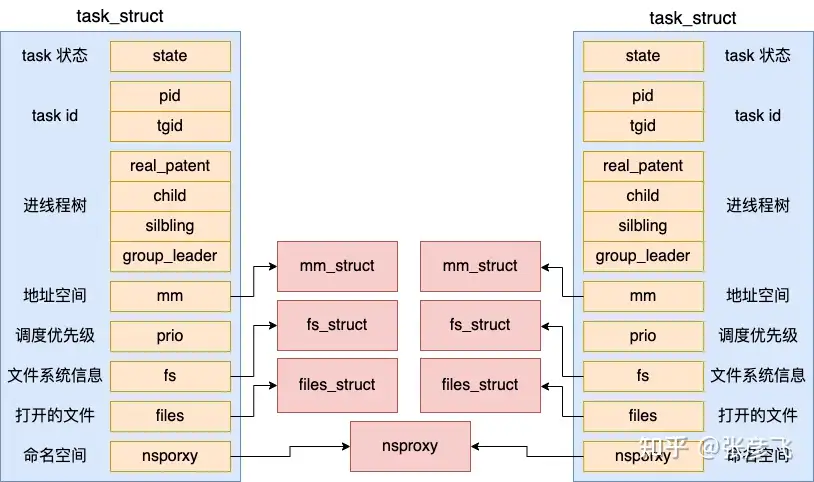
开篇的时候我说了,进程和线程的相同点要远远大于不同点。主要依据就是在 Linux 中,无论进程还是线程,都是抽象成了 task 任务,在源码里都是用 task_struct 结构来实现的。
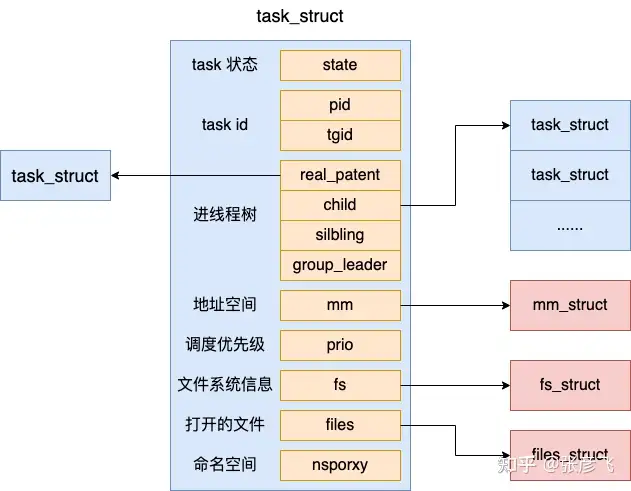
我们来看 task_struct 具体的定义,它位于 include/linux/sched.h
1 | |
这个数据结构已经在上一篇文章**《Linux进程是如何创建出来的?》**中,我们详细介绍过了。
对于线程来讲,所有的字段都是和进程一样的(本来就是一个结构体来表示的)。包括状态、pid、task 树关系、地址空间、文件系统信息、打开的文件信息等等字段,线程也都有。
这也就是我前面说的,进程和线程的相同点要远远大于不同点,本质上是同一个东西,都是一个 task_struct !正因为进程线程如此之相像,所以在 Linux 下的线程还有另外一个名字,叫轻量级进程。至于说轻量在哪儿,稍后我们再说。
这里我们稍微说一下 pid 和 tgid 这两个字段。在 Linux 中,每一个 task_struct 都需要被唯一的标识,它的 pid 就是唯一标识号。
1 | |
对于进程来说,这个 pid 就是我们平时常说的进程 pid。
对于线程来说,我们假如一个进程下创建了多个线程出来。那么每个线程的 pid 都是不同的。但是我们一般又需要记录线程是属于哪个进程的。这时候,tgid 就派上用场了,通过 tgid 字段来表示自己所归属的进程 ID。
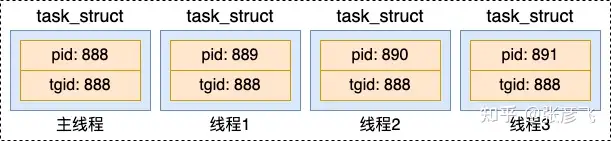
这样内核通过 tgid 可以知道线程属于哪个进程。
四、线程创建过程
要想知道进程和线程的区别到底在哪儿,我们从线程的创建过程来详细看一下。
4.1 回顾进程创建
在**《Linux进程是如何创建出来的?》**一文中我们了解了进程的创建过程。 事实上,进程线程创建的时候,使用的函数看起来不一样。但实际在底层实现上,最终都是使用同一个函数来实现的。
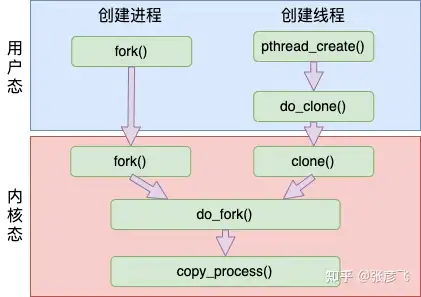
我们再简单回顾一下创建进程时 fork 系统调用的源码,fork 调用主要就是执行了 do_fork 函数。注意:fork 函数调用 do_fork 的传的参数分别是SIGCHLD、0,0,NULL,NULL。
1 | |
do_fork 函数又调用 copy_process 完成进程的创建。
1 | |
4**.2 线程的创建**
我们在本文第一小节里介绍到 lib 库函数 pthread_create 会调用到 clone 系统调用,为其传入了一组 flag。
1 | |
好,我们找到 clone 系统调用的实现。
1 | |
同样,do_fork 函数还是会执行到 copy_process 来完成实际的创建。
4.3 进程线程创建异同
可见和创建进程时使用的 fork 系统调用相比,创建线程的 clone 系统调用几乎和 fork 差不多,也一样使用的是内核里的 do_fork 函数,最后走到 copy_process 来完整创建。
不过创建过程的区别是二者在调用 do_fork 时传入的 clone_flags 里的标记不一样!。
- 创建进程时的 flag:仅有一个 SIGCHLD
- 创建线程时的 flag:包括 CLONE_VM、CLONE_FS、CLONE_FILES、CLONE_SIGNAL、CLONE_SETTLS、CLONE_PARENT_SETTID、CLONE_CHILD_CLEARTID、CLONE_SYSVSEM。
关于这些 flag 的含义,我们选几个关键的做一个简单的介绍,后面介绍 do_fork 细节的时候会再次涉及到。
- CLONE_VM: 新 task 和父进程共享地址空间
- CLONE_FS:新 task 和父进程共享文件系统信息
- CLONE_FILES:新 task 和父进程共享文件描述符表
这些 flag 会对 task_struct 产生啥影响,我们接着看接下来的内容。
五、揭秘 do_fork 系统调用
在本节中我们以动态的视角来看一下线程的创建过程.
前面我们看到,进程和线程创建都是调用内核中的 do_fork 函数来执行的。在 do_fork 的实现中,核心是一个 copy_process 函数,它以拷贝父进程(线程)的方式来生成一个新的 task_struct 出来。
1 | |
在创建完毕后,调用 wake_up_new_task 将新创建的任务添加到就绪队列中,等待调度器调度执行。这个代码很长,我对其进行了一定程度的精简。
1 | |
可见,copy_process 先是复制了一个新的 task_struct 出来,然后调用 copy_xxx 系列的函数对 task_struct 中的各种核心对象进行拷贝处理,还申请了 pid 。接下来我们分小节来查看该函数的每一个细节。
5.1 复制 task_struct 结构体
注意一下,上面调用 dup_task_struct 时传入的参数是 current,它表示的是当前任务。在 dup_task_struct 里,会申请一个新的 task_struct 内核对象,然后将当前任务复制给它。需要注意的是,这次拷贝只会拷贝 task_struct 结构体本身,它内部包含的 mm_struct 等成员不会被复制。
我们来简单看下具体的代码。
1 | |
其中 alloc_task_struct_node 用于在 slab 内核内存管理区中申请一块内存出来。关于 slab 机制请参考- 内核内存管理
1 | |
申请完内存后,调用 arch_dup_task_struct 进行内存拷贝。
1 | |
5.2 拷贝打开文件列表
我们先回忆一下前面的内容,创建线程调用 clone 系统调用的时候,传入了一堆的 flag,其中有一个就是 CLONE_FILES。如果传入了 CLONE_FILES 标记,就会复用当前进程的打开文件列表 - files 成员。

对于创建进程来讲,没有传入这个标志,就会新创建一个 files 成员出来。
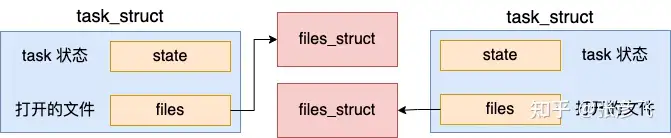
好了,我们继续看 copy_files 具体实现。
1 | |
从代码看出,如果指定了 CLONE_FILES(创建线程的时候),只是在原有的 files_struct 里面 +1 就算是完事了,指针不变,仍然是复用创建它的进程的 files_struct 对象。
这就是进程和线程的其中一个区别,对于进程来讲,每一个进程都需要独立的 files_struct。但是对于线程来讲,它是和创建它的线程复用 files_struct 的。
5.3 拷贝文件目录信息
再回忆一下创建线程的时候,传入的 flag 里也包括 CLONE_FS。如果指定了这个标志,就会复用当前进程的文件目录 - fs 成员。

对于创建进程来讲,没有传入这个标志,就会新创建一个 fs 出来。
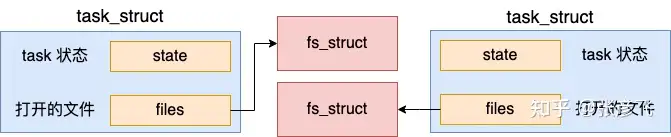
好,我们继续看 copy_fs 的实现。
1 | |
和 copy_files 函数类似,在 copy_fs 中如果指定了 CLONE_FS(创建线程的时候),并没有真正申请独立的 fs_struct 出来,近几年只是在原有的 fs 里的 users +1 就算是完事。
而在创建进程的时候,由于没有传递这个标志,会进入到 copy_fs_struct 函数中申请新的 fs_struct 并进行赋值拷贝。
5.4 拷贝内存地址空间
创建线程的时候带了 CLONE_VM 标志,而创建进程的时候没带。接下来在 copy_mm 函数 中会根据是否有这个标志来决定是该和当前线程共享一份地址空间 mm_struct,还是创建一份新的。
1 | |
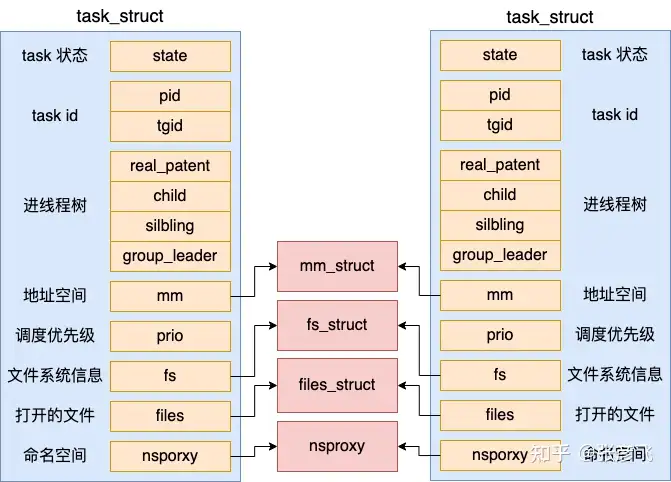
对于线程来讲,由于传入了 CLONE_VM 标记,所以不会申请新的 mm_struct 出来,而是共享其父进程的。

多线程程序中的所有线程都会共享其父进程的地址空间。
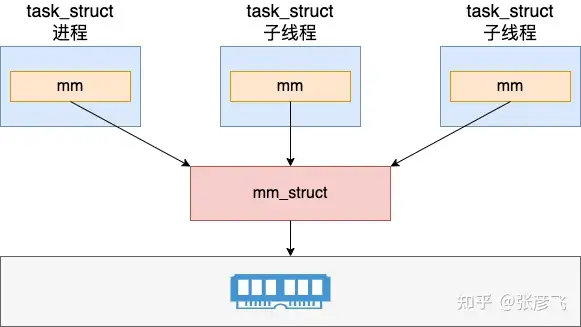
而对于多进程程序来说,每一个进程都有独立的 mm_struct(地址空间)。
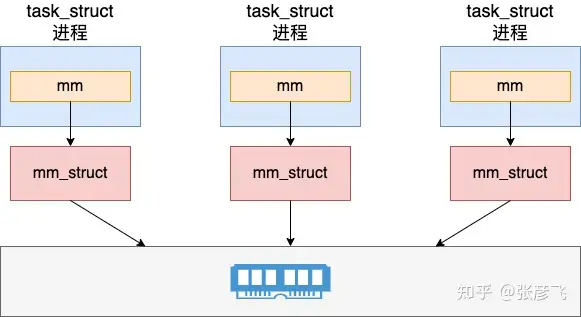
因为在内核中线程和进程都是用 task_struct 来表示,只不过线程和进程的区别是会和创建它的父进程共享打开文件列表、目录信息、虚拟地址空间等数据结构,会更轻量一些。所以在 Linux 下的线程也叫轻量级进程。
在打开文件列表、目录信息、内存虚拟地址空间中,内存虚拟地址空间是最重要的。因此区分一个 Task 任务该叫线程还是该叫进程,一般习惯上就看它是否有独立的地址空间。如果有,就叫做进程,没有,就叫做线程。
这里展开多说一句,对于内核任务来说,无论有多少个任务,其使用地址空间都是同一个。所以一般都叫内核线程,而不是内核进程。
六、 结论
创建线程的整个过程我们就介绍完了。回头总结一下,对于线程来讲,其地址空间 mm_struct、目录信息 fs_struct、打开文件列表 files_struct 都是和创建它的任务共享的。
但是对于进程来讲,地址空间 mm_struct、挂载点 fs_struct、打开文件列表 files_struct 都要是独立拥有的,都需要去申请内存并初始化它们。
总之,在 Linux 内核中并没有对线程做特殊处理,还是由 task_struct 来管理。从内核的角度看,线程本质上还是一个进程。只不过和普通进程比,稍微“轻量”了那么一些。