
Golang中map的实现原理
Golang中map的实现原理
什么是map?
map 的设计也被称为 “The dictionary problem”,它的任务是设计一种数据结构用来维护一个集合的数据,并且可以同时对集合进行增删查改的操作。最主要的数据结构有两种:哈希查找表(Hash table)、搜索树(Search tree)。
哈希查找表用一个哈希函数将 key 分配到不同的桶(bucket,也就是数组的不同 index)。这样,开销主要在哈希函数的计算以及数组的常数访问时间。在很多场景下,哈希查找表的性能很高。
哈希查找表一般会存在“碰撞”的问题,就是说不同的 key 被哈希到了同一个 bucket。一般的应对方法如下:
- 开放定址法
当冲突发生时,使用某种探查(亦称探测)技术在散列表中形成一个探查(测)序列。
沿此序列逐个单元地查找,直到找到给定 的关键字,或者碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。
查找时探查到开放的 地址则表明表中无待查的关键字,即查找失败。
- 再哈希法
同时构造多个不同的哈希函数。
- 链地址法(链表法)
将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 i 个单元中
因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
- 建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
go中 map 的底层如何实现
Go 语言采用的是哈希查找表,并且使用链表法解决哈希冲突。
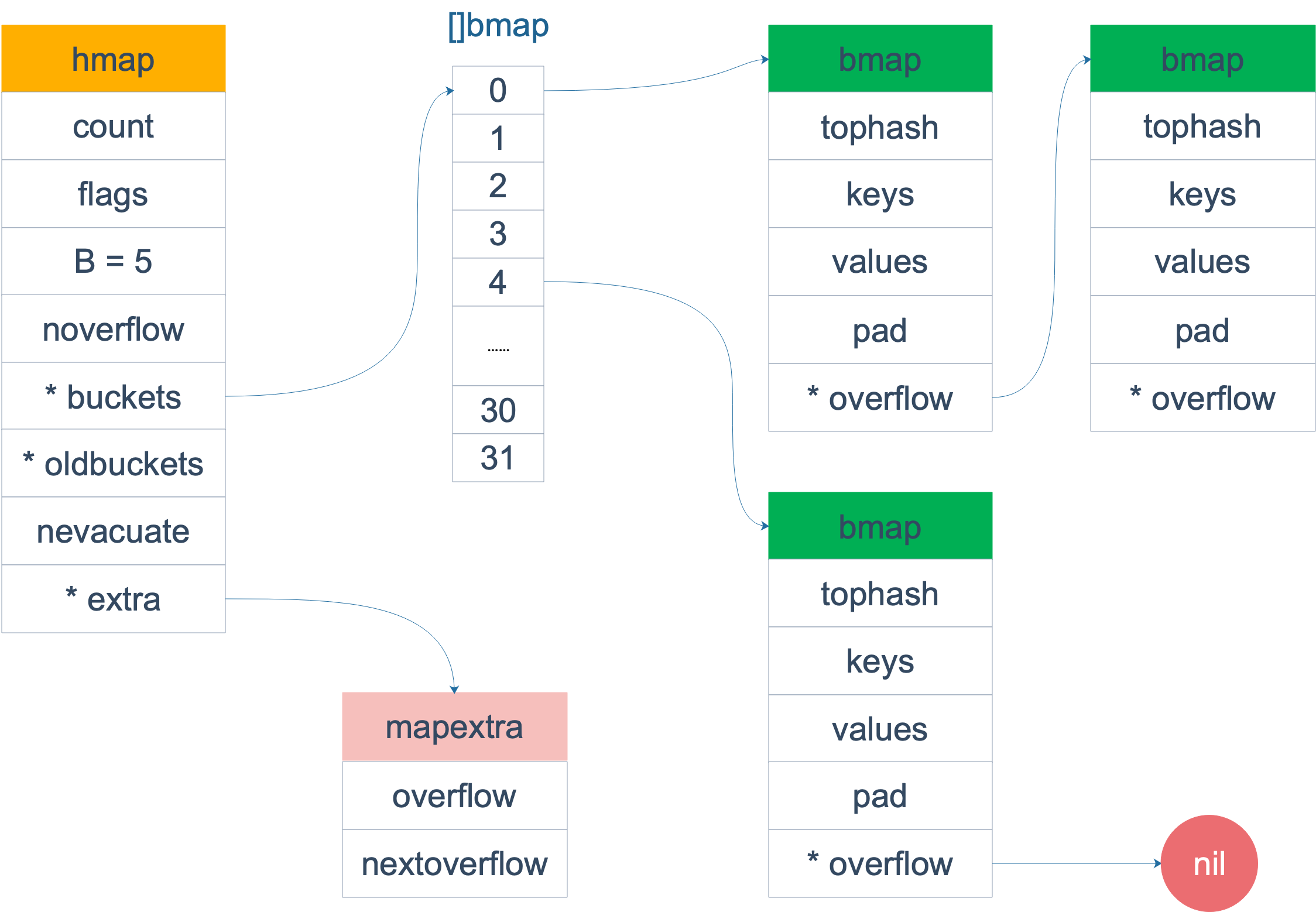
源码中 Go map 的结构体如下:
1 | |
- count 代表 map 中元素的数量
- flags 代表当前 map 的状态(是否处于正在写入的状态等)
- 2 的 B 次幂表示当前 map 中桶的数量,2^B = Buckets size
- noverflow 为 map 中溢出桶的数量。当溢出的桶太多时,map 会进行 same-size map growth,其实质是避免桶过大导致内存泄露。
- hash0 代表生成 hash 的随机数种子
- buckets 是指向当前 map 对应的桶的指针。
- oldbuckets 是在 map 扩容时存储旧桶的,当所有旧桶中的数据都已经转移到了新桶中时,则清空。
- nevacuate 在扩容时使用,用于标记当前旧桶中小于 nevacuate 的数据都已经转移到了新桶中。
- extra 存储 map 中的溢出桶。
其中buckets 是一个指针,最终它指向的是一个bmap结构体:
1 | |
tophash 通常包含此 buckets 中每个键的哈希值的最高字节。 如果 tophash[0] < minTopHash,则 tophash[0] 是一个桶疏散状态。
map 在编译期间确定 map 中 key、value 及桶的大小,因此在运行时仅仅通过指针操作就可以找到特定位置的元素。编译期动态地创建一个新的结构体:
1 | |
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。桶在存储的 tophash 字段后,会存储 key 数组和 value 数组。
整体结构图如下:
map的创建
go中map的创建,汇编底层调用的是 makemap 函数,主要做的工作就是初始化 hmap 结构体的各种字段,例如设置哈希种子 hash0 等。
源码如下:
1 | |
参考链接
1.https://golang.design/go-questions/map/principal/
2.深入理解 Go 语言的 map 实现原理,https://juejin.cn/post/7060128992870793246